


TL;DR: This session of Indexer Office Hours features an update on the refactoring of the QoS oracle from the GraphOps team and another edition of Delegator Watch, where indexers ask a delegator questions to help them attract more delegators.
Opening remarks
Hello everyone, and welcome to the latest edition of Indexer Office Hours! Today is April 16, and we’re here for episode 153.
GRTiQ 164
Catch the latest GRTiQ Podcast with Ariel Barmat, Vice President of Engineering at Edge & Node.
Repo watch
The latest updates to important repositories
Execution Layer Clients
- sfeth/fireeth: New releases:
- v2.4.3 :
- Fixes memory leak on Substreams execution (by bumping wazero dependency).
- Removes the need for substreams-tier1 blocktype auto-detection.
- Fixes missing error handling when writing output data to files. This could result in tier1 request just “hanging” waiting for the file never produced by tier2.
- Fixes handling of dstore error in tier1 ‘execout walker’ causing stalling issues on S3 or on unexpected storage errors.
- Prevents slow squashing when loading each segment from full KV store (can happen when a stage contains multiple stores).
- v2.4.4 :
- Fixes a possible panic() when a request is interrupted during the file loading phase of a squashing operation.
- Fixes a rare possibility of stalling if only some full KV store caches were deleted, but further segments were still present.
- Fixes stats counters for store operations time.
- Avalanche: New release v1.11.4 :
- Adds finer grained tracing of merkledb trie construction and hashing.
- Renamed MerkleDB.view.calculateNodeIDs to MerkleDB.view.applyValueChanges
- Added MerkleDB.view.calculateNodeChanges
- Added MerkleDB.view.hashChangedNodes
- Removes metrics for each chainID:
- avalanche_{chainID}_bs_eta_fetching_complete
- avalanche_{chainID}_block_eta_execution_complete
- avalanche_{chainID}_block_jobs_cache_get_count
- avalanche_{chainID}_block_jobs_cache_get_sum
- avalanche_{chainID}_block_jobs_cache_hit
- avalanche_{chainID}_block_jobs_cache_len
- avalanche_{chainID}_block_jobs_cache_miss
- avalanche_{chainID}_block_jobs_cache_portion_filled
- avalanche_{chainID}_block_jobs_cache_put_count
- avalanche_{chainID}_block_jobs_cache_put_sum
- Fixes p2p SDK handling of canceled AppRequest messages.
- Fixes merkledb crash recovery.
- Adds finer grained tracing of merkledb trie construction and hashing.
Graph Stack
- Graph Node: New release v0.35.0 :
- Declarative aggregations defined in the subgraph schema allow the developer to aggregate values on specific intervals using flexible aggregation functions.
- Add pause and resume to admin JSON-RPC API: support for explicit pausing and resuming of subgraph deployments with a field tracking the paused state in indexerStatuses.
- Support eth_getBalance calls in subgraph mappings: enables fetching the ETH balance of an address from the mappings using ethereum.getBalance(address).
- Add parentHash to _meta query: particularly useful when polling for data each block to verify the sequence of blocks.
- Parallel execution of all top-level queries in a single query body.
- The ElasticSearch index to which graph-node logs can now be configured with the GRAPH_ELASTIC_SEARCH_INDEX environment variable, which defaults to subgraph.
- Migration changing the type of health column to text.
- Disable eth_call_execution_time metric by default.
- Call revert_state_to whenever blockstream is restarted.
- Pruning performance improvement: only analyze when rebuilding.
- Disallow grafts within the reorg threshold.
- Optimize subgraph synced check-less.
- Improve error log.
- Update provider docs.
- Downgrade ‘Entity cache statistics’ log to trace.
- Do not clone MappingEventHandlers in match_and_decode.
- Make batching conditional on caught-up status.
- Remove hack in chain_head_listener.
- Increase sleep time in write queue processing.
- Memoize Batch.indirect_weight.
- Optionally track detailed indexing gas metrics in CSV.
- Do not use prefix comparisons for primary keys.
Matthew raised a question about the Graph Node release:
Q: Is it recommended for deployment on the network yet?
Answer:
For Arbitrum One (the mainnet as in the mainnet of The Graph, not Ethereum), what matters is the ratified Feature Matrix. Here, you’ll see a list of networks like Arbitrum One, Celo, and Avalanche—basically, all of the networks supported on the decentralized network, as well as which features are supported for those networks.
There’s also a version constraint for Graph Node, and the most up-to-date one is any version of Graph Node that is greater than or equal to 0.34.1 and less than 0.35.0. So, it’s exclusive of the 0.35.0 release, and I think what this means is that if, as an indexer, you were to get into some dispute and the cause of that dispute was that you were running 0.35.0 on Arbitrum One, you would be liable to be slashed. Because it’s not a ratified release for mainnet yet, so it’s encouraged to run on testnet.
Technically speaking, Graph Node updates must flow through the governance process and the feature support matrix.
Graph Orchestration Tooling
Join us every other Wednesday at 5 PM UTC for Launchpad Office Hours and get the latest updates on running Launchpad.
The next one is on April 24. Bring all your questions!
Blockchains Operator Upgrade Calendar
The Blockchains Operator Upgrade Calendar is your one-stop solution for tracking hard fork updates and scheduled maintenance for various protocols within The Graph ecosystem.
Simplify your upgrade process and never miss a deadline again.
Protocol watch
The latest updates on important changes to the protocol
Forum Governance
Contracts Repository
- [WIP] Horizon changes #944 (draft)
- [WIP/Experimental] Horizon Staking changes #956 (closed)
- [WIP] Horizon: add subgraph data service #946 (draft)
- [WIP] Horizon: add escrow and payments #968 (draft)
Network Subgraphs
- Core network subgraph: L2 tests, fixes to allocation status and startBlock for manifests (v1.1.0).
Open discussion
- Juan to share updates on the refactoring of the QoS Oracle
- Delegator Watch: Colson
QoS Oracle
Juan from the GraphOps team gave the current status of the QoS Oracle.
Current situation
Gateways are currently being run by Edge & Node, which report QoS data. The data flows through Edge & Node’s data science pipeline. The QoS data points from the pipeline get posted on-chain. Then, the QoS subgraph picks up the data and exposes it.
Here’s a visual representation of how the current data science pipeline is being used for this QoS Oracle.
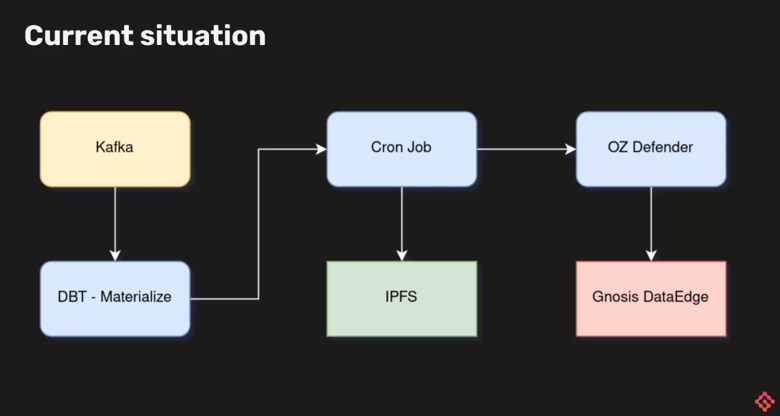
The gateway has Kafka messages coming out, which are then picked up by Materialize and DBT.
Then, some post-processing happens at the Materialize step, aggregating some of those Kafka messages into 5-minute data intervals for indexers, subgraphs, and users.
Then, after five minutes or whenever those buckets are ready, a Cron Job will post that data on IPFS and let the OZ Defender know that a transaction must go through to the Gnosis DataEdge with all of the IPFS hashes that are supposed to be handled afterward by the subgraph.
Known issues
He also highlighted some of the known issues with the QoS Oracle:
- Complex to properly set up
- Not originally intended for QoS data reporting, but rather for data analytics
- QoS reporting pipeline is deeply coupled with Edge & Node’s particular gateway setup
- Schema could be improved
Not a standalone QoS Oracle—it’s using an existing data science pipeline to report some QoS data.
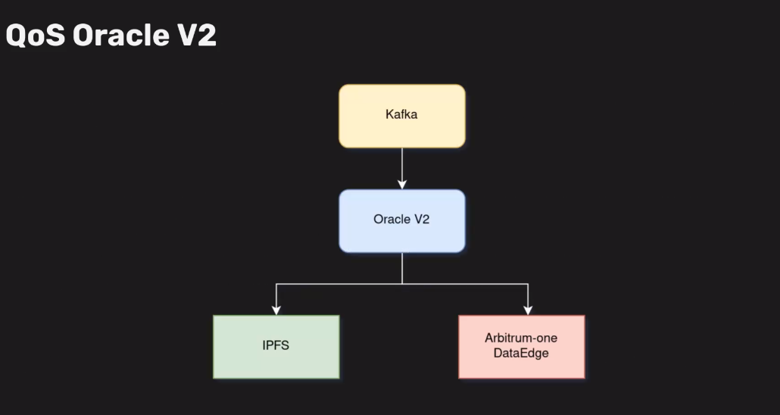
QoS Oracle V2
We decided to build a standalone Rust-based oracle that takes care of the relevant QoS reporting steps from this data science pipeline without having to run services like Materialize, having a Cron Job, Defender, and everything else.
We want a single Rust-based oracle that will take care of all these things, which should be possible, given that we won’t have all those extra steps for the data science outputs.
Another thing that we realized is that we would need to improve or enrich the Kafka messages to support some of the subgraph schema changes that we want. The existing subgraph only has the notion of index chain. So, the chain that the subgraph is indexing data from and a gateway ID, which isn’t unique, sometimes it just refers to, for example, gateway or testnet, and it just refers to the Edge & Node testnet gateway, which supposedly has all of the data for Rinkeby, Goerli, and Sepolia now.
We want to expand it a bit to have the index chains. Also, the chain that The Graph network is running on for that particular data point and unique identifiers for the gateway. So that any instance of a gateway would be differentiated in the data that we’re going to be posting on-chain.
We also want things like normalized lag metrics; by lag, I mean we currently have blocks behind. Blocks behind are not super useful for comparing across different chains like Arbitrum and Ethereum, which have different single blocks in each of those chains.
So comparing blocks behind across many data points doesn’t make sense currently, so having something like time behind, which is chain-agnostic, would be potentially a lot better, or another type of normalized metric if we can find another one.
Improved oracle post-processing to include new stats like percentiles for relevant statistics like latency, success rate, etc.
Visualization of easier setup:
Some QoS subgraph changes will be required:
- Improved schema to include:
- New fields from Kafka messages
- New post-processed data points from the oracle
- Potentially new QoS data grouping entities
- Modified topic and submitter whitelisting to accommodate for gateway decentralization
- Eventful DataEdge support
Questions
Indexers raised a few questions:
Q1: Will this be designed with future gateways in mind for World of Data Services?
Answer:
As long as those gateways have the same type of outputs for Kafka, they should work. The outputs are common, they’re not subgraph-specific, aside from the query data points being referred to as subgraph data points.
It’s just groupings over queries done to a single ID. It could be an ID for a subgraph, an ID for a file, or an ID for some other type of data service. That should be fairly reasonable.
And the data that’s coming there, its latency, blocks behind, like the freshness of the data, so that’s not super exclusive for different data services, but it’s not something we have considered as something that could not be working.
I assume they would work fine, but we’ll have to take care of that.
Q2: Is participating with the QoS Oracle optional for new gateway operators, or would it be required?
Answer:
Our position from GraphOps is that we think that any gateway operator should report QoS data. It shouldn’t be optional as QoS data should be free for anyone to look at.
It’s super helpful for indexers to know why they’re not being selected by the gateway. We think it’s common sense to have that free and open for everyone to take a look at, but again, it hasn’t been discussed, and properly ratified by The Council, which should, at the end of the day, be the one to ratify this.
Q3: What’s the target time resolution for the data? I find the old five-minute data point useful.
Answer:
We currently have the same target in mind, like the data points that are going to be coming out from Oracle should be the same as the old ones.
So, five-minute data point intervals, but we will also have, as with the old subgraph, daily data points. So, daily aggregations over all of those five-minute intervals and maybe weekly if it’s relevant, but we need to know if it’s relevant.
Currently, we plan on doing the five-minute, plus the daily aggregations on the subgraph.
Q4: Given operators in a gateway will eventually be permissionless, won’t we expect new gateway operators to just launch their own QoS oracle subgraph rather than permissioning them into a single QoS oracle subgraph?
Answer:
Ideally we have all of the data in a single subgraph, but they could have a separate subgraph for it, yes.
We might need a way, as part of the whitelisting that I mentioned previously, to find a way to make the registration part of a new submitter as permissionless as possible.
Given that The Council hasn’t ratified it yet, it might need to be progressively decentralized so that if we have a registry, it might start as a permission role to add new addresses as submitters.
Eventually, it might progress into a more decentralized and permissionless registry where anyone can submit or be added as an operator. But yes, they could deploy their own subgraph if they want to. Again, those things still need to be ratified.
Delegator Watch
Colson from Graph AdvocatesDAO was present to answer questions from indexers about delegating. After a brief introduction, here are some of the questions that were raised:
Q1: When you consider delegating to indexers, what are some key factors you consider as to which indexer you delegate to, and what factors influence your decision there?
Answer:
When I got in, I didn’t really know anything, so the first thing that I learned was there was this cool dashboard on the website where you could look at a lot of numbers that didn’t mean much to me at the time.
So, instead of going through all the numbers and learning about them, I joined these calls, and for me, the factor that really stood out to me was the community’s reputation.
So a lot of the people that are here, all the indexers, had a pretty big voice in the community and were always active in all the channels as well to help out community members and delegators, and those were the ones for me that I was like, okay, I think I trust these people with what they’re doing and then I eventually delegated to them.
Q2: Do you have any specific expectations or things you look for in terms of transparency, performance, and communication when picking an indexer? Are there specific things that call to you?
Answer:
Well, two things come to mind. One is that I would like to have an individual that I can speak to instead of just having the name of an indexer so that if there is something that I would like to ask or know, I could reach out to this indexer personally.
So, for example, in my username, you can see AdvocatesDAO is listed, so if there is an indexer that is big in The Graph ecosystem, I would like to see that in their name.
The other thing is that at the time, many people wanted to ask about the allocations, so I was also looking into if there were questions about allocations that the indexers responded to them. I think those are the two things that are very important to me.




No Comments