


TL;DR: The open discussion section covered three main topics:
- Gustavo from Semiotic Labs presented updates on indexer-rs and TAP, including new configuration options and features for indexer-service and indexer-agent.
- Ricky from Edge & Node shared a tutorial on data analytics for indexers, demonstrating tools for automating indexer operations and analyzing subgraph performance.
- Guillaume and Matthew from Pinax introduced a Kubernetes demo for deploying launchpad-charts, aimed at helping indexers get started with Kubernetes.
Opening remarks
Hello everyone, and welcome to episode 179 of Indexer Office Hours!
GRTiQ 190
Catch the GRTiQ Podcast with Anne Ahola Ward, co-founder and CEO of CircleClick Media, a digital marketing firm that focuses on growing startups and emerging tech companies.
Repo watch
The latest updates to important repositories
Execution Layer Clients
- Reth New release v1.1.0 :
- This release introduces a new default engine architecture for Ethereum chains, previously available only via the –engine.experimental flag. Nodes that prefer to maintain the old engine behavior must now use the –engine.legacy flag. The new architecture significantly improves performance near the tip of the chain, particularly in reducing engine_forkchoiceUpdated latency.
- Breaking changes: The ExExNotifications::recv and poll_recv methods have been removed, and users must now transition to ExExNotifications::with_head for exex notifications.
- Priority: Non-payload builders should prioritize (medium priority) updating to leverage the performance improvements. Low priority for payload builders.
- Heimdall: New release v1.0.10 :
- A low-priority release that includes several cleanups and additions of rpm packages.
- GraphOps is running this release on Polygon Amoy with no issues.
Consensus Layer Clients
Information on the different clients
- Teku: New release v24.10.1 :
- High priority hotfix (v24.10.1) addressing Teku startup failure with –validators-proposer-config option, incompatible with Windows, and includes breaking changes to metric names, now suffixed with “_total”.
- This release is incompatible with Windows.
Graph Stack
- Indexer Service & Agent (TS): New release v0.21.5 :
- This is the TypeScript indexer service repo.
- High-priority update addressing a large memory leak in the agent, improving TAP functionality, and adding new features to error logging and receipt validation, with significant improvements to documentation for multiple chains.
- GraphOps is running this release in their Graph Arbitrum Sepolia with no issues.
NOTE: The release process has changed. There are now two separate packages: indexer service and indexer TAP agent, so that users can run different versions for indexer service and indexer TAP agent.
- Indexer Service & Tap Agent (RS): New releases:
- This is the Rust indexer service repo.
- indexer-service-v1.1.0 :
- High-priority update introducing configuration flexibility, metrics improvements, and modifying PostgreSQL connection setup.
- You can specify the PostgreSQL URL connection as one URL or specify different components separately.
- Configuration flexibility addresses the ability to specify either a configuration file or environment variables. Previously, you always had to specify a configuration file.
- High-priority update introducing configuration flexibility, metrics improvements, and modifying PostgreSQL connection setup.
- indexer-service-v1.1.1 :
- Includes bug fix to use INFO as default level for logs.
- indexer-tap-agent-v1.1.0 :
- Includes bug fix to use INFO as default level for logs.
- indexer-tap-agent-v1.1.1 :
- High-priority update introducing configuration flexibility (you can now specify config via environment variables only), metrics improvements, and bug fixes, with potential breaking changes in configuration handling and database interactions, notably allowing config through files or environment variables and modifying PostgreSQL connection setup.
- indexer-service-v1.1.0 :
- This is the Rust indexer service repo.
- GraphOps is running indexer-service-v1.1.1 and indexer-tap-agent-v1.1.1 on our Graph Arbitrum Sepolia with no issues.
From the chat:
Marc-André | Ellipfra: 0.21.5 is failing here, at first glance it requires an unreleased graph-node version.
Ana | GraphOps replied: Ok, I’ll need to double-check that. Thank you for letting us know.
Marc-André | Ellipfra: indexer-agent: Null value resolved for non-null field paused #1025
Vincent | Data Nexus: We’re not running into this. I do remember running into this in the past. I don’t remember exactly what we might’ve done to fix the issue though :/
Figured out what we did. We actually patched a graph-node ourselves that we use exclusively for the indexer-agent status endpoint. Not the best UX obviously but it works if you’re in a pinch.
index 4d7e06779..a93f2e93c 100644
--- a/server/index-node/src/schema.graphql
+++ b/server/index-node/src/schema.graphql
@@ -71,7 +71,7 @@ type SubgraphIndexingStatus {
chains: [ChainIndexingStatus!]!
entityCount: BigInt!
node: String
- paused: Boolean!
+ paused: Boolean
historyBlocks: Int!
}
Marc-André | Ellipfra: I reverted to the specified commit suggested in the docs… good to know. thanks.
Launchpad Stack
- New chart versions released with enhanced features and bug fixes:
- Celo
- Heimdall
- Nimbus
- Lighthouse
- Graph-network-indexer
- Firehose-ethereum
- New stable versions of Ethereum, Gnosis, Celo, Monitoring, Arbitrum, Graph
Issues:
- Launchpad charts issues: View or report issues
- Launchpad namespaces issues: View or report issues
From the chat:
Matthew Darwin | Pinax: Just asking if anyone sees any problems with arbitrum-nitro. Johnathan | Pinax is trying to troubleshoot some weird RPC response issues.
Vincent | Data Nexus: What issues are you experiencing exactly?
Johnathan | Pinax: Empty response from RPC node.
Matthew Darwin | Pinax: It’s probably when sending a BOATLOAT of requests to the RPC at the same time.
Marc-André | Ellipfra: Other than it’s taking an obscene amount of space and resources, it seems fine…. performance is subpar generally.
Protocol watch
The latest updates on important changes to the protocol
Forum Research
Core dev updates:
- Pinax October 2024 Update
- Semiotic October 2024 Update
- Edge & Node’s September/October 2024 Update
- Geo October 2024 Update
- GraphOps Update October 2024
- StreamingFast October 2024 Update
- Messari October 2024 Update
Contracts Repository
- ❄️ Graph Horizon and Subgraph Service ❄️ #944 (open)
- chore(Horizon): add signers to TAPCollector #1060 (merged)
- fix: ensure subgraphNFT handles metadata with leading zeros correctly #577 (closed)
Open discussion
Agenda
- Update on Indexer-rs and TAP (new features)
- Data analytics tutorial for indexers
- Kubernetes demo and discussion
Indexer-rs and TAP [12:00]
Gustavo from Semiotic Labs presented an update with new features of indexer-rs.
A new release schedule for indexer-rs
- Instead of a big bundled release, we’re going to release as soon as a feature or bug fix is merged.
- This will result in faster fixes for issues reported.
- indexer-service-rs and indexer-tap-agent are now detached (even though they have the same version number right now) and will be released separately to accommodate when we have fixes that are only for one of them.
- Both share the same configuration, so every time we have a configuration update, both will receive it.
Repository and issues
New features
Most of the new features are related to quality of life for configuration.
New database configuration options
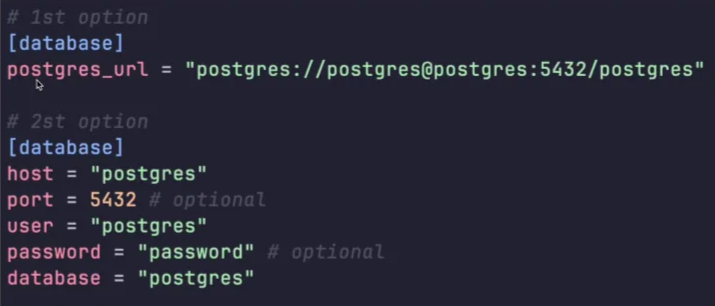
- Previously, you only had the first option where you needed to provide the PostgreSQL URL, but now you have a second option where instead of having the entire URL, you can have the host, port, user, password, and database.
New INDEXER_ prefix (that is backwards compatible)
- Some indexers were having trouble using environment variables because of tagging that required the indexer service prefix for the environment variables or the TAP agent prefix, and then if you wanted to share the same environment variables for both of them the same way we do with config, you couldn’t really do it. Now you can use a single one and it will work for both.

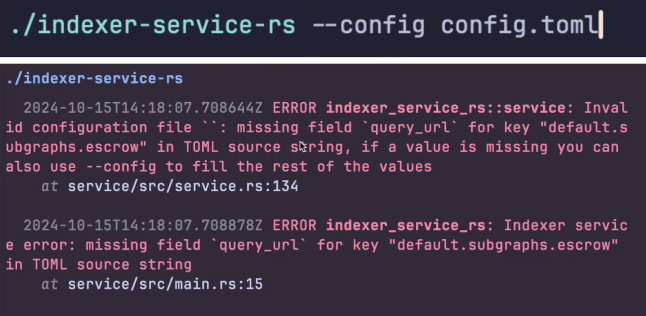
Removed requirement for –config args
- Now if you try to run without the config and you’re missing any environment variables, you’ll be told what field is missing and it will suggest you could also use the arguments config.
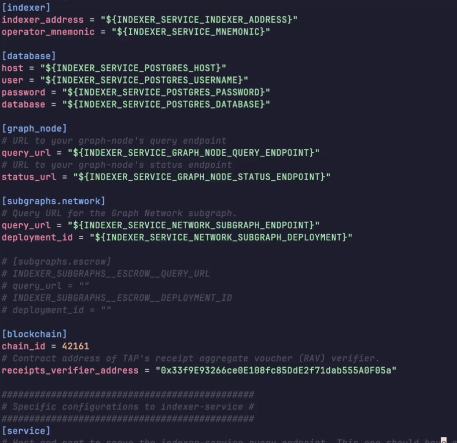
Inject any user-defined environment variable
- Previously if you wanted to use the environment variables, you would have to use the prefixes, but now you can mix part of environment variables with configuration.

Because of the previous feature, we created a migration configuration that maps from the older environment variables to the new configuration.
Migration configuration
- We have a suggested configuration (on our repo) to easily migrate from your previous configuration to a new one.
- docs/migration-config/arbitrum
- docs/migration-config/arbitrum-sepolia
- We still recommend using the configuration overtime.
From the chat:
chris.eth | GraphOps: That’s really nice, Gustavo | Semiotic Labs!
Marc-André | Ellipfra: These are nice improvements.
Other features and fixes
- We fixed a bug where you had to provide RUST_LOG to see logs, it’s now INFO by default
- Tap-agent
- Better tracking of pending receipts (buffer tracking).
- Denies the sender again if it’s removed from the database.
- Stores error reason in DB in case a receipt fails.
- Indexer-service
- Added metrics for Prometheus/Grafana.
- Different from previous TypeScript indexer service because we’re now using the recommended naming. Because of the breaking change we could update and have better naming.
- Indexer-agent
- Fixed errors where it was not fetching all pages for internal subgraph queries.
- Don’t redeem if the escrow account has not enough funds.
Questions [21:29]
chris.eth | GraphOps: With TAP payments, gateways are not fully permissionless (even if at the protocol-level we have permissionless payers). Indexers need to permission new gateways (by adding their tap-aggregator endpoint config for their signer key), or core devs need to coordinate with new gateways to roll out new software defaults that include that tap-aggregator config. Is there a path to remove this permissioning dependency?
Gustavo answers: Here’s an issue that we currently have on that, and I would love to have your feedback: [Feat.Req] Gateway discovery and verification protocol #342.
We are planning to create what we’re calling a gateway discovery feature and verification protocol. We didn’t allow just anyone to provide the TAP aggregator from the beginning because somehow you need to trust that the TAP aggregator is running and we didn’t have any verification.
So, for example, you could have a TAP aggregator endpoint, but when you try to aggregate your receipts into a RAV (request aggregate voucher), it would fail. The problem with that is you would lose this initial RAV or the amount that you’re willing to lose, you would actually lose for every bad gateway. So that’s why we decided that in the beginning, indexers should trust or at least allow the gateway and provide the TAP aggregator themselves.
The gateway discovery and verification protocol would have a gateway approach an indexer, send its TAP aggregator, and try to send a few queries to show the indexer that it is able to aggregate into RAVs.
Please have a look at the issue and let’s have more discussion about how we plan to do this.
From the chat:
Vince | Nodeify: steal-it-all-gateway, no updated needed, all your base belong to me until you block? Feels like there needs to be a happy gateway list or discovery of them.
chris.eth | GraphOps: Indexer <> gateway relationships are trust-minimized due to TAP, so it’s quite safe for indexers. However the consumer <> gateway relationship is 100% trusted, so gateway operators are really important actors in our ecosystem.
Who’s on TAP?
Matthew Darwin | Pinax posted: Vince | Nodeify are you on TAP already? Who else is on TAP?
Vince | Nodeify: I am not yet, still tuning my pg db from sharding migration few weeks ago. Fixing dashboards, etc.
Dashboard for indexer-service-rs metrics
Vincent | Data Nexus: FYI, I made a dashboard for the new indexer-service-rs metrics.
- Click link to Discord and then select Show Chat (chat bubble) at top right of screen for message with code.
calinah | GraphOps: Is this the same one you shared recently?
Vincent | Data Nexus: Yes, I shared it the other week after the commits were merged, before the release was cut.
Data analytics tutorial for indexers [27:14]
Ricky, a data scientist at Edge & Node, presented on analytics from an indexer’s perspective. He shared a tutorial he’s created: Data Analytics for Indexers. Watch for another session from Ricky in the future!
Ricky:
I started my own indexer to better understand the data more hands-on: rickydata-indexer.eth.
I’ve worked on automating parts of my indexer and building useful data tools for the indexer community.
I’ll start by sharing a tutorial I made that walks through pretty much every aspect of the automation I have so far for my indexer. The tutorial is meant for complete beginners and uses the R programming language, which is somewhat similar to Python.
Watch Ricky demonstrate the tutorial at 29:00.
- The first section, Getting Started, gives you all the tools you need to understand the steps that come later in the tutorial.
- Walk through using real query volume data from the QoS subgraph, which shows us query volume ~10 minutes behind real time, compared to on-chain query volume which can take 28 epochs, or never appear on-chain.
- A great resource with full daily data for every subgraph starting around September 20. You can see query fees, query count and then you have it done by date and subgraph ID.
- See tools for summarizing and transforming data, then walk through some visualizations.
- Close Allocations shows how to pull active allocations, do GraphQL queries and see how that works, pull current epoch, exclude high volume subgraphs, and close allocations.
- Synced Subgraphs shows which subgraphs are currently synced on your indexer. Figure out which subgraphs you can allocate on and which you have synced.
- Indexing Rewards Proportions pulls signal and allocated tokens so we can calculate the indexing rewards proportions for each subgraph.
- Query Fee Proportions takes you further to look at the query fees for different subgraphs (pulled from the QoS subgraph) and identify what are the best opportunities from that point of view.
- Available Tokens Data From Subgraph pulls how many tokens an indexer has for new allocations.
- Active Allocations Data From Subgraph looks at which allocations an indexer already has so we don’t allocate more tokens towards those.
- Calculate New Allocations outlines Ricky’s current mechanism for allocating: 100 GRT at a time for the best deal, recalculate, and keep going through that process.
- Allocate does the actual allocations.
Additional Data Tools [35:38]
Ricky shared the Data Tools page of a website he’s been working on.
- Subgraph Volume Data Download allows you to download the most recent 100,000 rows directly from the Quality of Service subgraph. See what are the highest increases in query volume lately, filter it by chain, and use that to find some good query volume opportunities to index.
- Curation Signal Optimizer needs a little more work because it doesn’t cover everything on the curation side but it provides the APR that you’re currently making on your signal, and tells you which are low performing signals. This is based on the 10% you make from query fees as a curator.
- It includes subgraphs that don’t have indexing rewards enabled on them so that needs to be fixed.
- Indexer Data Download allows you to extract raw, full historical data for your indexer to help track rewards over time or create visualizations.
Feedback from the indexer community would help a lot, so please share with Ricky.
Note: Ricky is doing this as an independent contributor. This is not Edge & Node capacity.
Watch for a Know Your Indexer forum post coming soon!
Questions [39:37]
Abel | GraphOps: Ricky, that was incredible. I don’t know if you’ve had a chance to look in the chat but the indexers are completely blown away. You’ve clearly taken it to another level when it comes to analytics. We may need to have a dedicated IOH session to help other indexers level up because everyone is loving it.
Vincent | Data Nexus: How much GRT are you allocating? Do you think the allocate 100GRT at a time strategy might run into performance issues with indexers with a lot of GRT to allocate?
Ricky answers: Within my script, I have established a maximum cap threshold where I only allocate up to 10% of my total stake size towards one single subgraph. No particular reason for that, other people can play around with different things, but that’s what I settled on to maximize rewards without exposing myself to a ton of risk of those rewards going down.
I think the other aspect is increasing the rate at which the automation runs, where it can kind of more intelligently start closing out allocations of same epochs and maybe getting more sophisticated.
Vincent | Data Nexus: Yeah, I think I’m good. Awesome presentation, thanks!
Vince | Nodeify: TLDR: data scientists should be banned from being indexers, too good.
Slimchance: Delegate to Ricky here: rickydata-indexer.eth.
Kubernetes Office Hours [43:56]
Guillaume and Matthew from Pinax shared some resources to make it easier for indexers to get started with Kubernetes.
- Testing Kubernetes apps with kind
- Bootstrapping a cluster with FluxCD
- Using Helm with Flux to deploy launchpad-charts
Guillaume:
This is meant to be an introduction to Kubernetes and how we do things at Pinax (but scaled down).
Here’s a Kubernetes IOH Demo repo that you can use to get started.
This repository demonstrates how to use FluxCD to deploy launchpad-charts.
The repo is replicable so that you can try it out, play with kind.
I’m using Flux, kind, and a tilt file. This will create a Kubernetes cluster with kind. So this is not meant for production, but more for development. kind stands for Kubernetes and Docker, so as long as you have Docker installed on your machine, it’s going to create a cluster that you can develop on, test stuff, and deploy applications in Kubernetes.
The cluster will be deployed with a bunch of components: Cilium, Cilium Envoy, load balancer IDs. It’s also going to bootstrap Flux.
For this cluster, when working with Flux, you need to have all your infrastructure as code. Instead of doing Docker Compose, you can use Flux and Kubernetes to scale and deploy as many blockchains or as many components as you want.
The more blockchains and the more nodes you have, the harder it is to scale with Docker Compose and the more manual the process becomes, so if you switch to Kubernetes, it’s easier to do new blockchains and add stuff to your cluster.
Infrastructure:
- Monitoring stack: kube-prometheus-stack
- Launchpad charts
- PostgreSQL operator to bootstrap PostgreSQL databases inside of Kubernetes
- cert-manager to do TLS automatically with issuers
- Automation to update charts
Watch the cluster going at 50:09.
Matthew | Pinax: Thanks, Guillaume. That was definitely rushed, so I think we’re going to need to run through this again in a future session. But the idea here is trying to build something that lets people get started with Kubernetes and get over the “Kubernetes is complicated and I don’t have time to look at it” problem. This way you have something to play with that is all running on your local machine, so it’s pretty amazing. You can clone the repo and get this stuff running without too much work.
Guillaume: Hopefully, it will automagically work. 😁
Abel | GraphOps: We’ll definitely schedule another session with more time. Might even be worth going through the demo again once people have had some time to look it over.
Matthew: What would also be helpful is whatever questions people have on getting started. What information do you need to know to get going with Kubernetes? There are a lot of concepts that Guillaume went over quickly, talking about infrastructure as code and the system automatically deploying everything when you change things in GitHub. So no running Kubectl or manually deploying things.
It also takes a different approach than how Launchpad does things. People have different approaches to do things in Kubernetes. If we were to survey 20 indexers, you would probably get 20 different flavors of how that works, so part of the idea here is to show parts of what we’re doing and then we can help explain why things are done that way.
Chris | GraphOps: Just as a minor clarification there, Matthew. Launchpad is super modular and there are quite a few components. There are obviously Launchpad charts, which you are using in this example. This is a slightly different approach to how Launchpad Namespaces orchestrates those charts, and yeah, excited to have discussions about the tradeoffs there.
Matthew: This is the great part about Launchpad, it’s very modular, so people can pick up the pieces they like and do other things if they want something else. Vince wants to do things another way, which is totally fine, and Vince, I know you’ve talked to a bunch of different people who have different opinions on how things work.
Vince | Nodeify: Yeah, I think this is a great intro no matter what though, because you can watch a lot of intros, but truly the only way [to learn] is to play with it and bang your head against your keyboard, and I think this is a great way to do it.
From the chat:
chris.eth | GraphOps: Here’s the graph-node chart that Guillaume deployed: Graph-Node Helm Chart
There’s also a graph-network-indexer chart that packages indexer-agent, indexer-service-rs, and indexer-tap-agent: Graph-Network-Indexer Helm Chart
Vince | Nodeify: Argo CD, FluxCD, Launchpad. A religious question.
chris.eth | GraphOps: Argo + Helmfile gives you both. But yes, it is religious.
Vince | Nodeify: Nano
Guillaume Cléroux | Pinax: I only use ed, everything else is bloat.
Vincent | Data Nexus: I think the hot one nowadays is Neovim, lol.





No Comments