


Last Updated on February 19, 2025 by louis
Learn how to use our Ethereum dataset with Snowflake to analyze blockchain data for insights like daily active users and top contracts.
TL;DR: Discover how to analyze blockchain data efficiently using datasets from Pinax. Learn how our solution simplifies access to Ethereum data through Parquet files and managed databases like Snowflake, enabling SQL queries for extracting valuable insights like daily active users and top contract activities.
We’re excited to demo a product that’s transforming blockchain data analysis: Datasets on The Graph, integrated with Snowflake. In this post, we’ll explore the problems we’re tackling, our innovative solutions, how people can consume our datasets, and our vision for the future.
For more on our datasets, visit:
- Pinax Datasets Offer Simple Solution to Accessing Blockchain Data
- Pinax Datasets Offer Superior Simplicity with Parquet and S3
What is the problem?
Blockchains generate vast amounts of data—volumes that are large and challenging to manage. Extracting this data, especially when detailed interactions from RPC nodes are involved, requires custom instrumentation.
Analysts used to traditional tools like SQL struggle with the complexities of blockchain data extraction. Add to that the challenge of handling multiple blockchain networks, and it becomes an operational burden.
Accessing this data efficiently also means minimizing the need to download massive datasets. That’s why we need a solution that enables a data store, so you can query just the data you need.
What is our solution?
We leverage two powerful technologies: Firehose and Substreams. These services run on The Graph and allow for efficient extraction and storage of blockchain data. We start by defining block schemas for various chains (EVM-based, Solana, Bitcoin), and export them into Parquet files—essentially flat files with database properties. These files are hosted on AWS S3 or other S3-compatible buckets.
To make data more accessible, we don’t stop at raw storage. We also list the data on Snowflake Marketplace. You can query the raw data from S3 or connect directly to Snowflake, a hosted managed database, to run SQL queries on managed datasets. This versatility allows you to access blockchain data in ways that you’re comfortable with.
How can you consume datasets?
You have multiple options to access the data. You can:
- Load raw data from S3 into your database using external tables or direct copy methods.
- Directly query the data in managed databases like Snowflake using SQL.
- Use Python libraries like Polars or pandas to programmatically read individual Parquet files.
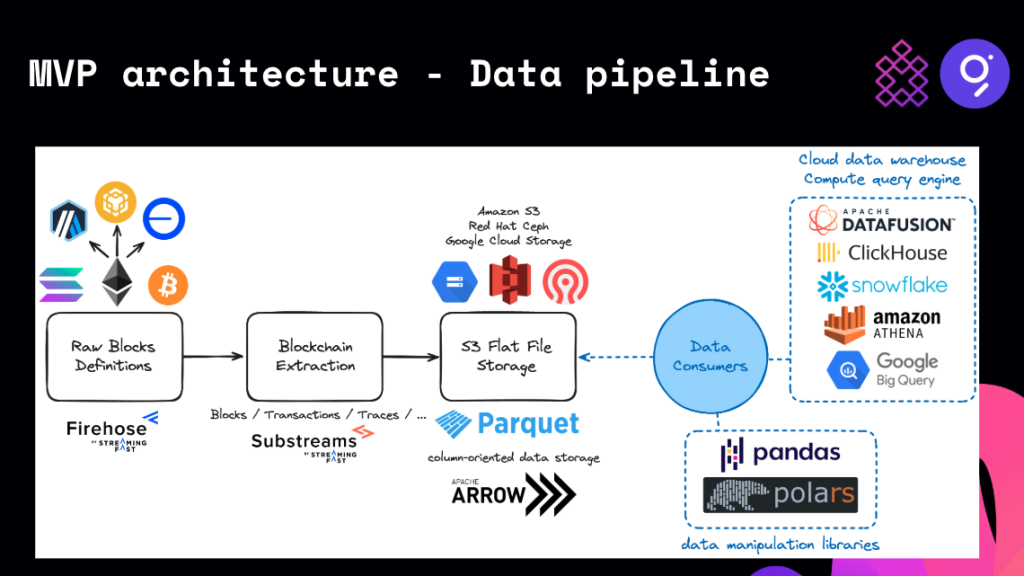
Architecture overview
The data pipeline starts with Firehose, which enables instrumentation for blockchain datasets, creating a standardized block type that flows through Substreams. Here, we define the schema for different data types (blocks, transaction traces, logs) and convert them into Parquet files.
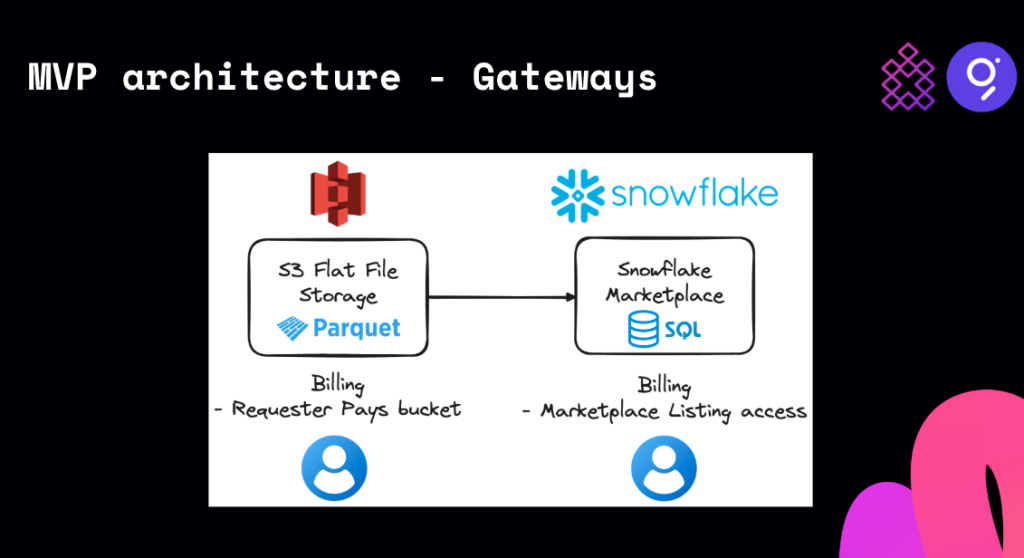
The extracted data can be hosted on S3 and then consumed in various ways, such as SQL compute engines or Python libraries. We also support two different gateway approaches:
- Requester Pays: Billing is based on S3 storage usage, allowing you to pay for the specific amount of data you access.
- Snowflake Marketplace: You can access the datasets directly without copying, with the added convenience of SQL-ready managed databases.
Snowflake integration demo [Timestamp 5:04]
Snowflake provides a marketplace where you can easily find datasets. For example, searching “Ethereum” will show listings from well-known data providers. Our Ethereum dataset is free to try, with no listing fee applied.
You can preview the data to get familiar with its structure by viewing tables such as blocks, logs, and transaction hashes. For now, Snowflake hosts this data in a single region (US East N. Virginia), and we plan to add more regions in the future as needed.
In our demo, we show how to use Snowflake’s Python notebooks to analyze daily active users on Ethereum, visualizing the data using pandas. We also explore top contracts by activity, highlighting how easy it is to dive into contract-level details.
What are our future plans?
Currently, we have Ethereum hosted on Snowflake and S3. We’re actively expanding to support other EVM chains like Base, Arbitrum, BSC, and Polygon, as well as non-EVM chains such as Solana and Bitcoin. Plus, we aim to shorten the data refresh rate from 24 hours to as low as possible, making near-real-time analytics a reality.
We’re excited to keep building and evolving this product, expanding support to more blockchains and enhancing real-time capabilities to make blockchain data accessible to everyone—from analysts to developers.
Depending on customer feedback and the success of our datasets pilot on Snowflake, you may see datasets as a fully supported data service on The Graph in the future.
If you’re interested in exploring how we can simplify blockchain data access for your needs, visit our website or contact us to learn more. Request a demo to see how we can transform your blockchain data insights.
Remember, our Ethereum dataset is free to try on Snowflake!
💡 This article answers questions like:
- What is a blockchain dataset?
- What can an analyst do with datasets hosted on Snowflake?
- What are the different ways you can access the data in a dataset?
- How can you try our Ethereum limited history dataset for free?





No Comments