


Last Updated on January 8, 2025 by Pinax Team
Discover how we’re building our datasets for exceptional efficiency, ease of use, and performance.
TL;DR: Pinax's datasets simplify blockchain data access using Parquet files and S3. This combination provides efficient storage, accelerated query performance, and seamless integration with various analytics tools. Raw blockchain data is structured using SQL schema, making it readily available for analysis. Our datasets offer a user-friendly solution for accessing and analyzing complex blockchain information across multiple industries.
In a previous blog post, we introduced Pinax’s datasets and how they will simplify access to blockchain data. In this post, we’ll dive into the tools and structures that make our datasets so powerful, like Parquet files and SQL schema. We’ll discuss how Pinax uses Parquet files for efficient data storage and the comprehensive SQL schema that underpins our raw blockchain datasets. Find out how we plan to empower data analysts with user-friendly, cutting-edge technology.
Overview of Pinax datasets
Pinax datasets make blockchain data easily accessible to remove barriers for people who want to analyze blockchain information but may not have specialized tools or infrastructure. We leverage Parquet files hosted on S3 to enable professionals across various fields—from macro analytics to AI chatbots and finance—to focus on insights rather than data wrangling.
We’ve designed our datasets to be compatible with existing analytics tools, allowing analysts to easily plug and play with their current setups. This means you can seamlessly integrate our datasets into your existing workflow using Amazon S3 as external tables. External tables are widely supported across various databases so that you can query data directly from S3 without extensive setup or custom infrastructure, which makes data management less complex.
Try our Ethereum dataset: free to try as a 30-day trial on Snowflake.
Parquet files for efficiency
Accessing, processing, and analyzing blockchain data can be challenging, especially as the technology continues to grow across industries, and data volume and complexity increase. Pinax can help with easy-to-use datasets that simplify access, designed with both technical and non-technical users in mind. Central to our streamlined approach are Parquet files—a powerful columnar storage format that improves efficiency and scalability, especially for large datasets.
But what exactly are Parquet files, and why are they so critical for accessing blockchain data?
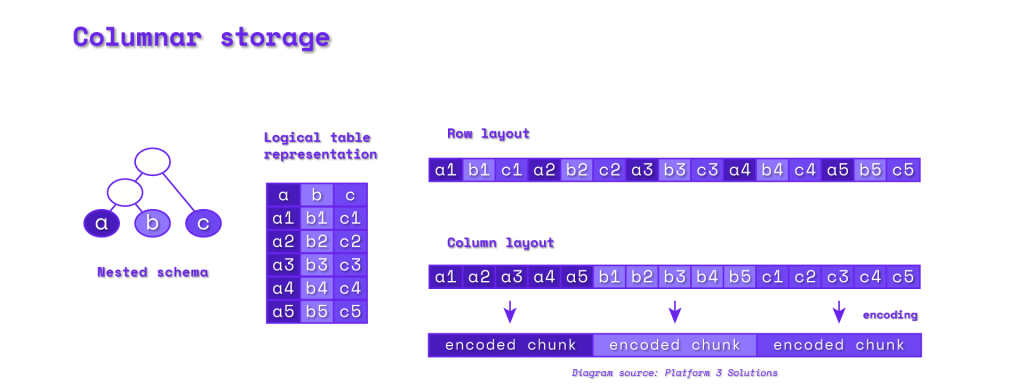
What are Parquet files?
Parquet is a columnar storage file format widely used in data processing for its efficient compression and performance. Unlike row-based storage formats, which store data sequentially, Parquet optimizes storage and query performance by organizing data in columns, making it particularly effective for analytics.
Why are Parquet files crucial for blockchain data?
The columnar format of Parquet files makes them ideal for managing the complex, high-volume datasets in blockchain. By enabling selective column queries, Parquet improves query speed and reduces storage costs, offering a practical solution for handling terabyte-scale blockchain data.
Key benefits include:
- Efficient storage: Parquet compresses data without losing quality, reducing storage costs—especially beneficial for large blockchain datasets.
- Faster queries: Column-based storage allows analysts to access only needed data, enhancing performance for tools like Messari.
- Broad compatibility: Parquet integrates seamlessly with various analytics tools, supporting workflows across SQL, Python, R, and more.
How Pinax uses Parquet files
Pinax delivers blockchain data in a format designed for easy use:
- Seamless integration: We provide raw blockchain data in Parquet format, allowing users to integrate data smoothly into existing pipelines.
- Up-to-date insights: Datasets are updated daily, ensuring users have access to the latest blockchain data.
- Enhanced usability: Parquet’s familiar format simplifies the analysis process, enabling analysts to focus on insights rather than infrastructure.
Pinax Pilot Program Update: Messari Mainnet Testing
Our datasets pilot program continues to shape up well, with new advancements aimed at refining data access and performance. Here’s the latest on our setup:
- Data segregation & access options: With the S3 external table setup, analysts can manage data access independently. Options include copying S3 data into custom tables, connecting directly to the S3 external table, or using our pre-configured Snowflake views. Additionally, data can be downloaded locally for on-disk processing, providing flexibility in data handling.
- Minimal involvement in custom requirements: This setup keeps Pinax’s role light; we focus primarily on ensuring data completeness and accurate schema definitions while analysts retain control over specific data needs.
- Data sync & formatting: Automated S3 sync uploads ensure data is formatted for readability, allowing for the creation of custom views on top of datasets to better match analysis needs.
- Performance optimization: We continue to test configurations to improve query performance over large datasets, including reorganizing partitions to enhance speed.
Expanding use cases for Pinax datasets
Pinax datasets have the potential to serve a range of applications:
- Macro analytics: Platforms like Messari and Snowflake benefit from our datasets by seamlessly incorporating blockchain insights into broader market analyses.
- Accounting: Blockchain records provide a transparent and immutable ledger, making them invaluable for accounting and audit purposes.
- Blockchain forensics: Datasets can aid forensic investigators in tracing transactions, uncovering fraud, and monitoring suspicious activities on the blockchain.
- AI chatbots and LLMs: Access to structured blockchain data serves as high-quality training data for AI models, particularly large language models (LLMs) aimed at understanding blockchain-related queries or performing analytics.
- Finance analytics: DeFi applications can integrate Pinax data to display historical trading stats, lending insights for better-informed financial decisions.
Understanding raw blockchain data
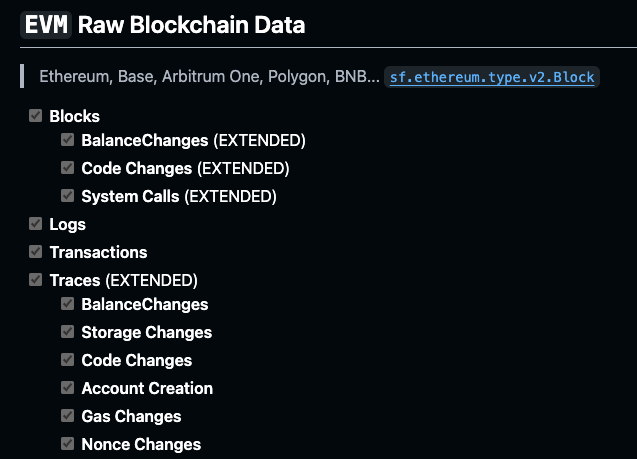
Blockchain data comes in raw form, capturing all essential transactions and interactions on the network. Pinax provides access to extended foundational Ethereum data tables, such as blocks, transactions, extended traces, and logs. Our datasets allow for granular analysis, from tracking individual transactions to understanding trends across blocks, making them ideal for applications across various sectors.
The role of Protobuf in structuring blockchain data
For efficient data access, Pinax utilizes Protobuf (.proto) files to structure blockchain data directly into Parquet format. This approach eliminates the need for SQL schemas, enabling streamlined and scalable data access across diverse applications.
Pinax’s EVM Protobuf schema defines granular data structures for tracking EVM activity, including blocks, transactions, logs, and state changes. These Protobuf definitions ensure that Parquet files are well organized, allowing users to efficiently analyze blockchain interactions with precision and depth.
To explore check out Pinax’s Substreams Rawblocks GitHub.
Practical applications of the SQL schema
To illustrate how this SQL schema can be applied in real-world analysis, here are some sample queries that demonstrate how to retrieve specific insights from blockchain data.
Daily Active Users
This query calculates the number of unique active users per minute on a specific date by analyzing transaction data in the Ethereum blockchain dataset.
SELECT
block_date,
count(distinct "from") AS user
FROM eth.transactions
GROUP BY block_date
ORDER BY block_date ASC
Top Contracts
This query retrieves the top 10 contracts with the most transactions on a specific date, ordered by transaction count.
SELECT
"to" AS contract,
count(*) AS transactions
FROM ethereum.transactions
WHERE block_date = '2024-10-01'
GROUP BY contract
ORDER BY transactions DESC
LIMIT 10;
ERC-20 Transfers
This query counts the total number of successful ERC-20 token transfers (using Transfer and TransferFrom functions) per day within a specified date range.
SELECT
block_date,
count(*) as total
FROM
eth.traces
WHERE
tx_success = true AND
SUBSTR(input, 1, 10) IN ('0xa9059cbb', '0x23b872dd') // Transfer and TransferFrom
AND block_date >= '2024-11-01' AND block_date <= '2024-12-01'
GROUP BY block_date
ORDER BY block_date;
Hosting with Snowflake for enhanced accessibility
Pinax datasets are available on Snowflake, a cloud-based data platform known for its ease of use and powerful integration capabilities. Snowflake Marketplace allows you to integrate blockchain data into your workflow with minimal setup.
Snowflake Marketplace will make our datasets available to a wider audience, facilitating greater data accessibility across industries.
Interested in trying our datasets?
Blockchain data is often seen as challenging to access and analyze, but Pinax datasets will change this mindset. Our focus is on user-friendly formats and easy access to make blockchain data accessible for multiple uses, ranging from finance analytics to AI model training.
If you’re interested in exploring how we can simplify blockchain data access for your needs, visit our website or reach out to us to learn more. Request a demo to see how we can transform your blockchain data insights.
Remember, our Ethereum dataset is free to try as a 30-day trial on Snowflake!
💡 This article answers questions like:
- How is Pinax building its blockchain datasets for ease of use and optimal performance?
- What types of industries and use cases will benefit from Pinax's datasets?
- What are Parquet files?
- Why are Parquet files suited for blockchain data?
- What's captured in raw blockchain data?
- What is the role of SQL schema in structuring blockchain data?
- How can I try a Pinax dataset for free?





No Comments