


TL;DR: Yaniv introduced GRC-20, a new standard for knowledge graphs that can be used across applications. Christophe shared the current implementation, including three major components: a sink that uses Substreams to read on-chain events, Neo4j for storing entities, and a GraphQL API server for exposing data to consumer apps. Indexers will be able to choose which spaces they want to index rather than indexing the entire global graph, with future plans to implement AI capabilities.
Opening remarks
Hello everyone, and welcome to episode 189 of Indexer Office Hours!
GRTiQ Podcasts 201 and 202
Catch the highlights from all the episodes in 2024 in the two-part series:
- The Best of 2024 (Part 1) (episodes 151 to 175)
- The Best of 2024 (Part 2) (episodes 176 to 200)
⬇️ Skip straight to the open discussion ⬇️
Repo watch
The latest updates to important repositories
Execution Layer Clients
- Erigon New release v2.61.0 :
- Date: 2025-01-06 15:58:36 UTC
- The release includes updates to implement Pectra network fork specifications and an upgraded Golang version in the Dockerfile. Operators should review these changes for compliance and performance improvements.
- Urgency indicator: Yellow
- Urgency reason: Important updates, but not immediately critical.
- Reth New release v1.1.5 :
- Date: 2025-01-07 13:50:34 UTC
- In version 1.1.5, the legacy engine implementation is no longer the default, and support for it has been entirely dropped. This release includes significant performance improvements, bug fixes, and breaking API changes, which may impact existing applications and workflows.
- Urgency indicator: Red
- Urgency reason: Legacy support removal requires immediate user action.
- Nethermind: New release v1.30.3 :
- Date: 2025-01-04 12:43:40 UTC
- This release requires all nodes on OP mainnet and Base mainnet to upgrade to Nethermind v1.30.3 and op-node v1.10.2 by January 9, 2025, due to the Holocene hardfork. Failure to upgrade will result in incorrect node functionality.
- Urgency indicator: Red
- Urgency reason: Mandatory hardfork required for correct functionality.
- Avalanche: New release v1.12.1 :
- Date: 2024-12-17 23:21:23 UTC
- This release fixes P-chain mempool verification to prevent transactions from exceeding chain capacity, ensuring network integrity. It also introduces a configurable option for PebbleDB and includes various enhancements and corrections, mainly focused on optimization and documentation.
- Urgency indicator: Yellow
- Urgency reason: Important fixes and enhancements; not critical.
- Arbitrum-nitro New release v3.3.1 :
- Date: 2025-01-06 18:54:45 UTC
- Version 3.3.1 fixes a tracing regression from v3.2.1, enhancing reliability for blockchain operations. Users should utilize the correct Docker image based on their validator setup.
- Urgency indicator: Yellow
- Urgency reason: Important fix for tracing regression.
From the chat:
Matthew Darwin | Pinax: So many Nitro releases yesterday. It is recommended by the Offchain Labs team to upgrade to Nitro 3.3.0 or later.
Vincent | Data Nexus: I saw that, lol. Not sure I’d like to upgrade right away after seeing the frequency of those releases.
Matthew Darwin | Pinax: We had to patch earlier Nitro version to avoid it crashing.
Consensus Layer Clients
Information on the different clients
- Teku: New release 24.12.1 :
- Date: 2024-12-18 11:04:40 UTC
- Release 24.12.1 includes critical bug fixes for gas checks, API responses, and libp2p message sizes, ensuring better operational stability. Operators should note that the upcoming version, 25.1.0, will introduce breaking changes in metric names.
- Urgency indicator: Yellow
- Urgency reason: Important bug fixes, prepare for upcoming changes.
Graph Stack
- Indexer Service & Tap Agent (RS): New releases:
- indexer-tap-agent-v1.7.4 :
- Date: 2024-12-18 22:55:11 UTC
- Includes bug fixes that enhance stability by adding receipts timeout configuration, shutting down the tap-agent on database connection loss, and ensuring message listening starts up correctly after initialization.
- Urgency indicator: Yellow
- Urgency reason: Important stability fixes, not immediately critical.
- indexer-service-v1.4.0 :
- Date: 2024-12-18 22:55:10 UTC
- Adds a graph-indexed header to subgraph query responses and improves request status metrics. It also includes fixes for middleware routing errors and status code updates. Overall, these updates enhance functionality but do not impact critical operations.
- Urgency indicator: Yellow
- Urgency reason: Improvements and fixes, not immediately critical.
- indexer-tap-agent-v1.7.4 :
GraphOps is running this release on testnet and mainnet, and has encountered a bug related to serving queries directly to indexer service with a free auth token when a subgraph is not allocated to (500 internal server error), but do not let it stop you from upgrading.
Protocol watch
The latest updates on important changes to the protocol
Forum Governance
- Request for information about disputes #GDR-22
- Request for information about disputes #GDR-24
- Some interesting technical discussions on this one.
- GRC-20: Knowledge Graph
- Some more updates have been added.
Contracts Repository
- chore: add over delegated test for SubgraphService #1082 (open)
- fix: add whenNotPaused to closeStaleAllocation #1081 (open)
Open discussion [10:11]
GRC-20: Knowledge Graph
Yaniv and Christophe are here to talk about the GRC-20 standard.
Yaniv: The mission at The Graph has always been to make web3 real. We’ve been hard at work, and I think that we’ll really be able to say that we did it this year. Today, I’d like to introduce everyone to GRC-20 and then make sure that you all understand what we’re releasing, what it means for The Graph, and what it means for you as indexers.
I want to start with a quick recap of this post that I published in the middle of last year, Knowledge graphs are web3. It’s always good to start with a bit of context. If you look at what The Graph is mostly used for today, and as an industry where most of the traction is, it really is in DeFi. Most of the subgraphs we have are kind of DeFi-based, and we oscillate between questions like:
- Is all of this decentralized technology only good for DeFi?
- Is DeFi the only killer app?
- Was the whole web3 idea even real?
We really do believe in web3, but we think we need to understand exactly what it’s supposed to be, and as The Graph, we really want to enable this brand-new platform. Web3 is a new platform for decentralized applications, and the core properties of this platform are verifiability, openness, and composability.
We believe we should be able to rebuild every type of application to be verifiable, open, and composable, and we don’t want these applications to live in silos or be controlled by corporations.
And yet, if we look around and we’re like, where are all the web3 apps? What are the apps that we’re using every day that are on web3, what apps are our friends and family, people who aren’t even in the crypto industry, using every day that are on web3? Obviously, we haven’t crossed that chasm yet.
The claim of this blog post (Knowledge graphs are web3) is that the thing that’s been missing is composability. We have pretty good versions of verifiability and openness; you can sign transactions with cryptographic signatures, and we have decentralized networks like The Graph Network, where everything is open and people can come in and provide services. But what we haven’t really had is the composability.
Most of the consumers of subgraphs are the developers who built the underlying protocols. There are a lot of these verticalized apps. Maybe a developer built a lending protocol, and then a lending subgraph, and then a lending application, and it’s a kind of vertical thing, but it’s not really an ultra-composable thing, and most of the use cases are financial in nature. We believe these properties of verifiability, openness, and composability are really going to be useful for every type of application.
You can think about any generalized information, and you want to have access to public knowledge and information, you want to be able to use it in your applications, you want to be able to contribute to it, and that’s what we want to enable. We believe that knowledge graphs are the solution to this.
At the end of the post, we talk about the Semantic Web, which is the original vision of the original architects of the web to build this kind of global decentralized knowledge graph. Tim Berners-Lee always wanted it to be a graph of data, or he called it a web of data instead of a web of pages, and then on top of that global web of data, you could build any kind of applications.
There are a few reasons why that didn’t work the first time around. I listed three in the post:
- The main standard that was created by the original architects of the web, RDF and SPARQL, had some issues that hindered its adoption.
- You need pretty robust governance processes or standards if you want to have different applications that are building on shared schemas and sharing data. You need to have ways for those people to coordinate and there weren’t good solutions for that.
- No incentives to run the infrastructure. The centralized platforms out-competed because they could monetize better and then invest that into better infrastructure and user interfaces.
This is why I believe this vision of an open, decentralized web failed, and things recentralized. I think we finally have the solutions.
The first problem is basically about the standard for the knowledge graph data and for querying it, and that’s where GRC-20 comes in.
Introducing GRC-20: A Knowledge Graph Standard for Web3 [16:18]
We published this blog post and we published a new standard for knowledge graphs called GRC-20.
The blog post goes over some of the use cases. I’ll give you a high-level understanding for why we need a new standard, why not use RDF? I’ll give you my three reasons (there are actually quite a lot of reasons, but here are my three biggest ones):
- If you actually look at the RDF standard, it is quite complex and academic. To actually implement the standard, there’s a lot of what I would call incidental complexity. This makes people not want to use it.
- RDF doesn’t support the property graph model. When we look at graphs, we have nodes and edges; we call them entities and relations. With the property graph model, the edges themselves can have properties on them and that’s super powerful to be able to describe facts about the connections between things. It allows you to create more powerful graphs. RDF doesn’t support that, and it’s an important feature that modern graph databases support, which is why we have that in GRC-20.
- The IDs for entities in RDF are basically resource locators, and usually what they do is point to a server. They’ll tell you if you want information about this entity, go to this server, and that’s where you can get the information; it’ll give you back the data. Essentially, that’s a mutable, server-specific way of getting the data. It’s like the difference between HTTP and IPFS. In our case, we’re not doing content addressing, but we do not want to go to a single server operator who’s basically the source of truth—whatever they give you back is the answer. That’s not a web3 way of looking at things. We want the IDs to be decoupled from any server operator.
RDF has had over 20 years and it’s been mostly niche, but graphs themselves are huge, and I think more and more people are understanding the power of graphs. Especially in the age of AI, knowledge graphs and graph databases like Neo4j are becoming extremely popular because they’re the perfect tool to use for things like LLMs.
For The Graph, this was always the vision. Not a lot of people know this, but the first version of Graph Node was actually a triple store, so we knew there was something to this idea, but we didn’t have all the pieces at the beginning.
Then DeFi took off, and we started really optimizing for DeFi use cases, but now we believe it’s a good time to go back and finish building the pieces and really enabling web3.
The Components of GRC-20 [20:42]
One of the things I’d like to communicate is the distinction between Geo and The Graph.
Ultimately, we think knowledge is an important first-class thing, and we’d love for everyone to understand the distinction between information and knowledge.
We think that knowledge is something that needs to live natively on The Graph. The idea is for Geo to be just one application. We want Geo to be a kind of generalized browser, a generalized application, but really, we want to empower developers to build any kind of application that consumes knowledge from the knowledge graph and can contribute knowledge to the knowledge graph.
- Geo is one application that allows you to interact with the global decentralized knowledge graph.
- GRC-20 is a standard for knowledge graphs that can be used across applications.
Entities and relations [22:18]
The first-class concepts are entities and relations, so everything can be described as an entity. Any person, place, thing, idea, or concept can be represented as an entity, and then these entities have relations between them.
For example, if you have a content marketing course with many lessons, each lesson is its own entity, and there are relations between the lessons and the course; maybe there are different topics. So what makes this a graph is you have these nodes and these edges between them.

Triples [22:58]
The atomic unit of data in a knowledge graph in GRC-20 is a triple. A triple is an entity, attribute, value.
There are apps like Obsidian that are very graphy and cool, but these apps allow you to define local graphs, and what we’re trying to do is build a decentralized global knowledge graph. All knowledge is interconnected, right? There really are not artificial boundaries between things. With information, you can always want to take a step further because everything is interconnected, and we want to have this global knowledge graph.
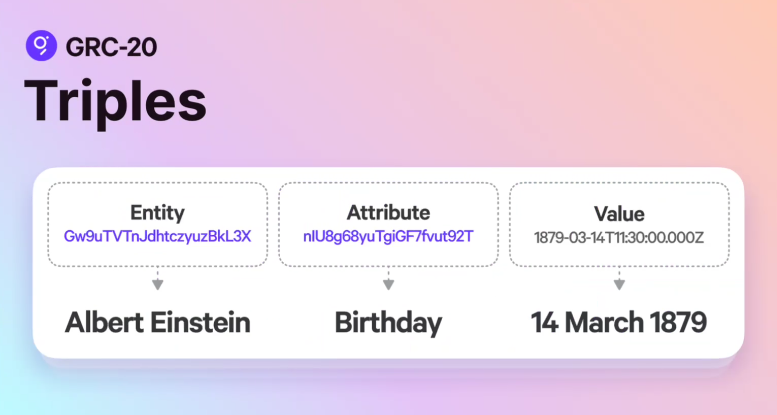
Every entity has a global unique ID and this is quite powerful. If I want to refer to the city of San Francisco, and every application uses a different ID to refer to San Francisco, how are we supposed to make sense of that? Especially because different words could mean different things in different contexts, and so having global unique IDs, you know if we’re talking about the same thing or not. And all the different applications, what have they said about this particular thing, and then that can allow you to aggregate things and really get to composability. This is what we need to be able to do.
It’s not just the entities that have the global unique IDs, it’s also the attributes. So anytime we’re talking about a birthday, for example, maybe this is the attribute ID for the birthday property, and so we could be talking about Albert Einstein’s birthday, but we could also be talking about the birthday of, for example, a pet. Albert Einstein is a person, but maybe a pet also has a birthday. You can have properties that themselves are distinct from the entity.
Then you have a value.
This is a triple; it’s a single data point:
Entity —> Albert Einstein
Attribute —> Birthday
Value —> 14 March 1879
One of the principles of GRC-20 is we want applications to be able to produce knowledge, and you can think of knowledge as being a collection of triples and relations. So you produce knowledge, like here’s a bunch of facts about something that I care about. I can describe these facts and then I can publish them, and then that knowledge is interoperable, so any application can interpret and understand the knowledge that has been produced by other applications.
Types [26:24]
We have these native types:
- Text
- Number
- Checkbox
- URL
- Time
- Point
Then what we allow you to do is define these higher-level types. All of you are familiar with PostgreSQL, which is like a relational database, so you have these tables, and the tables are kind of like types, and they’re relational, so they have relations between them. But relational databases are very strict and you have to know the structure upfront. You have to know these are the columns on the table and if you want to modify the columns, it can be an involved migration process. If someone wants to add data to the database, to the table, that doesn’t conform to the exact columns that are in the table, you’re going to get an error.
If you wanted interoperability between thousands of different apps, the data is never going to look exactly like that one table that you have, and so you’re constantly going to be dealing with these mismatches and trying to figure out how to get that composability, that interoperability.
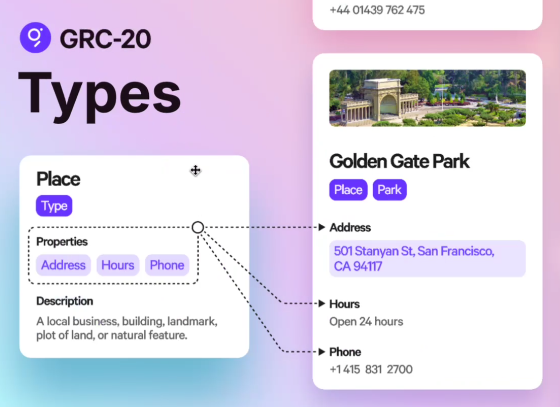
GRC-20 approaches types so that it’s a way of providing structure. The difference between data and information is that information adds structure to data. For example, if we’re talking about a place and a place has these properties: an address, hours of operation, a phone number. So this is a structure, we know that places may have these fields, but they don’t have to. It’s kind of like a hint, but we don’t enforce these structures.
With GRC-20, entities can have many types. Golden Gate can be a place and a park, so a place can define fields that are relevant to places, and a park can define fields that are relevant to parks. This gives us a flexible way of adding structure to information without limiting and breaking composability and making it so you can really have many different applications that are producing and consuming this stuff.
Learn more about relations and the strength of property graphs at 28:56.
Full spec [29:35]
A few things that are relevant for you all.
We use Protobufs for the encoding. We specify how to encode the data, decode it, and how to define things like relations. The type system is there, all the stuff is defined.
We have an active Forum post for discussion and feedback.
What’s coming next
We published this as the first step. Everything depends on the serialization, as we can’t have any knowledge on the knowledge graph until this has been frozen. We want this to be an open standard, so we did this first.
We’re going to have an announcement coming up soon where we go more into governance.
Two top-level goals for The Graph
More useful knowledge and information, better organized
- Web3 to start to be usable across every industry, academic field, and part of society.
- Use cases like news:
- It’s hard to know what to trust when you’re looking at the news.
- Is there journalist bias?
- Fake news.
- Anything that can help us better structure and understand what’s happening in the world where it’s so noisy.
- Use cases like education:
- People have lost a lot of faith in universities and want to come up with ways to create new types of educational systems and courses.
- Change how we organize and curate curriculum and decide as communities what counts as a good education and what kind of certifications we want to have.
- Tools for people to form into groups to organize knowledge that’s useful to them.
This would be one of the North Star metrics to signal the health and utility of The Graph Network.
Enabling interoperable consumer apps
- On top of this global graph of knowledge and information, we want to enable lots of different consumer applications.
- Developers should be able to build these apps and they should be interoperable.
We’re going to be releasing a framework for developers to build these consumer apps on top of The Graph, which is going to be really exciting for changing the types of applications people can build, and I think it’s going to redefine the web3 space in a major way.
Governing public knowledge [34:35]
If you want to have a global decentralized knowledge graph, with public knowledge and information, who determines what is true, and what kind of systems can we build that people can trust?
This most recent blog post (linked above) addresses all the questions people may have when I start to talk about this stuff. Is it even feasible? Is it desirable?
I start with the set of claims about knowledge:
- There is such a thing as objective truth.
- No person or organization can claim to know absolutely what the truth is.
- Knowledge is not evenly distributed. Some people have more than others.
- Acquiring knowledge is a challenging process that requires determination, curiosity, humility, intelligence, and hard work.
(See the complete list in the post.)
You start with these claims, and then you understand the design goals, and then we build it up from personal spaces (they’re open; anyone can create one) to public spaces (should have public governance). How these spaces can be related to each other. How we structure knowledge and pluralism, curation—these are really core concepts. Please read this post for an understanding of what was a missing piece: governance.
Current Implementation of GRC-20 [36:34]
Christophe (stopher | Playgrounds on Discord): I’m mainly working on the indexer that presumably you guys will be using to index data from the knowledge graph and then serve it to consumer apps.
Let’s dive into the technical side of how GRC-20 is currently implemented. This diagram explains how GRC-20 currently works and where the indexer fits into the whole picture.
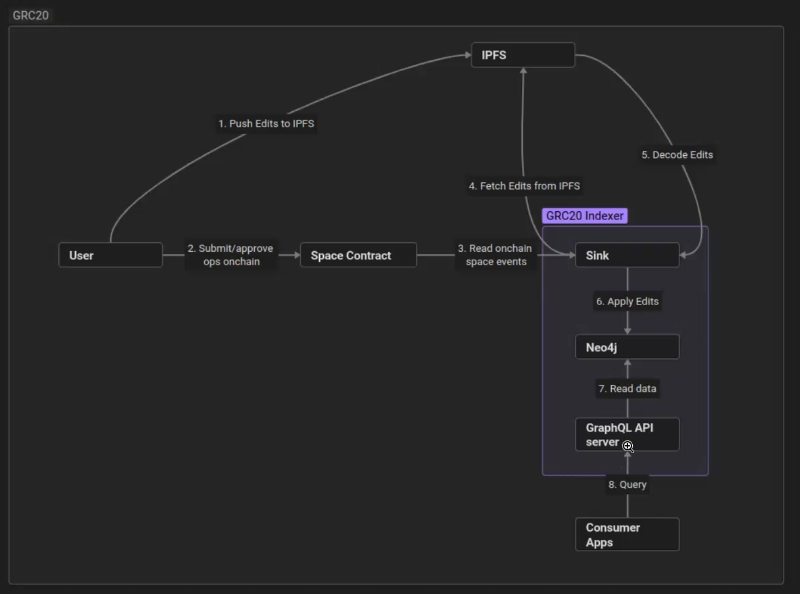
As Yaniv mentioned, knowledge is divided into specific spaces. Spaces can be personal or public; in public spaces, there is a governance process to decide what knowledge is submitted to the space.
All edits that are made to a space, whether that be creating a triple, editing a triple, deleting a triple, creating relations, etc., are uploaded to IPFS, and then they are submitted for approval on chain with the IPFS hash of the edit. Once the edits have been approved, and whatever the edits contain becomes canonical knowledge for the space, then it is the responsibility of the indexer to fetch those edits from IPFS and then apply them to their own representation of the knowledge graph.
There are three major parts to the indexer stack. A sink uses Substreams to read on-chain events related to different spaces, and the sink is also responsible for fetching data from IPFS. Then the sink will apply the edits to the entities for that space that are stored in Neo4j. The other big component is the GraphQL API server, which exposes the data from Neo4j to the consumer app.
Here’s the codebase if you want to check it out and play around with it: GRC20 Neo4j Indexer repo
- It’s currently under the Playgrounds organization, but we’ll presumably move it to The Graph protocol in the next few weeks.
- In the repo, you’ll find a Docker Compose file that you can use to easily spin up the three components I just talked about. You will have to use a Substreams provider. We’ve been using one hosted by Pinax. Thank you very much, Pinax, for that. But once you have that, you can run the whole stack locally, and you can play around with both the Neo4j instance and the GraphQL API that will expose that Neo4j data.
Matthew Darwin | Pinax posted: Anyone is welcome to connect to the Pinax Substreams API for testing.
Christophe: Now I will go over the database and the API. For those who are not familiar with Neo4j, it is a NoSQL schema-less database that is purpose-built for highly linked data. What that means is that relations are first-class citizens in Neo4j. There’s no schema; all entities in the database are based on documents, and you query them using pattern matching.
Watch an example of a query at 41:41.
Instead of having to do joins to traverse relationships between entities, you actually pattern match on the relations themselves.
Watch how we’re actually representing GRC-20 data in Neo4j at 44:18.
Yaniv: This is very much still in progress, this knowledge graph data service. We wanted to give everyone an overview of GRC-20 and show you as things are developing. This as-is is not ready for consumption yet; you’re getting an early preview while we’re still in development.
It’s a very graphic kind of API, and then what we’re going to be building on top is an SDK that looks much more typed for each application. If I’m building an education app, I might want to define the schema for my application, and I should be able to define that however I want. Then I have an API that looks exactly the way that my application wants. If I’m defining courses, lessons, and tutorials, that’s how I’ll interact with it. I’ll also have really great typing, so if I’m building in TypeScript, I’ll have autocomplete and all of this kind of stuff, so it’s going to feel very natural, very intuitive, and a great experience for developers.
What’s coming soon
Christophe: In terms of the work remaining to bring this to production, we still need to implement a few changes in the Protobuf models. We also want to have much better observability, so I know as indexers, you love to connect everything to Prometheus and have metrics and logs—that’s still left to do. As for the AI capabilities that Yaniv talked about, you might be familiar with the concept of ragging and, more specifically, GraphRAG. Luckily for us, Neo4j has semantic search via embeddings as a first-class citizen, so the idea of generating embeddings for all nodes in the knowledge graph is on the table. We’re pretty excited about this, as it’s going to enable some pretty crazy AI apps.
Yaniv: Yeah, it’s really huge. It turns out that LLMs are really great interfaces, but if you want to get accurate answers, you need to have the LLM hit some kind of source of truth from which it returns the answer to you. Graphs are the best way of representing complex relationships and states of things, and it’s a perfect complement for LLMs. You ask it a question, it figures out what the right query is from the graph, it can get a bunch of relevant information, and then it can synthesize an accurate response for you. This becomes a foundational thing that enables AI in a way that is grounded in truth and in a way that’s decentralized, so it’s not one company deciding what’s the truth, it’s a decentralized graph that the AI can use.
Christophe: Some unsolved questions and problems we’re still tackling include how to shard the system so that indexers don’t have to index all spaces. They could selectively index different spaces. And then there’s also the question of whether we want to separate governance into a separate data service.
Yaniv: We want to get this into your hands. One of the things that is going to make this different is the use of Neo4j, so it would be interesting to know if any indexers want to play around with Neo4j and help with some Op stuff there. As far as how this changes indexing, we want to move to a model where indexers can choose which spaces they want to index, and then you’re choosing what subset of the global graph you want to index. If you want to index everything that is related to your city or country, maybe you can do that across every industry if that’s how you want to select your portion of the graph. Then, you’ll be more efficient in answering queries that are geographically based.
The next two months are going to be massive rolling this stuff out, leading up to the web3 app framework, getting third-party devs building apps on this stuff, and hopefully having all of you running the infrastructure.
Q&A [55:31]
stake-machine.eth: How does it compare to IPLD?
Yaniv: Interesting question. IPLD is linked data, but it’s really meant for more like immutable linked data. That’s kind of an interesting thing. IPFS is really for immutable stuff. The content addressing thing only works so much, but the truth is the state of things is always changing. For example, let’s say I want to know the population of the city of San Francisco or what events are happening in the city today. Someone could have added an event a minute ago and what’s the content address for that and the link? The model doesn’t really work for dynamic applications. The query is more, ok, I have the ID for the city of San Francisco, I want to know the events, and this is the information that I want. With knowledge graphs, you have entities, the relations or the IDs of the other entities as opposed to being these content address links.
chris.eth | GraphOps: What is the difference between information and knowledge?
Yaniv: Knowledge is when you link and label information to achieve a higher level of understanding. You could think of subgraphs as basically being like information. Essentially, there’s a structure defined by the schema and then you’re taking this raw blockchain data and then you’re indexing, you’re giving it structure, and so that’s the transformation into information. But you can have all this information in your database and you’re missing context: you have these users, you have these transactions, was one of these transactions happening as a result of a hack? Is one of these users a power user of this protocol? Or a first-time user? You can think of those as labels, enriching things. And then the interconnections between things. Think about how your own mind works when you’re learning things. What is knowledge in your own head? You’re making connections between things: oh this is kind of like that; oh wait, this contradicts this other thing that I heard. For example, say you had a video of a talk that was given at a conference and you could transcribe that, so already linking the transcription to the video, that’s a connection, and then you have the transcription of all the individual sentences and so those are individual things that you can connect. And then for each one, you could say, “hey is this thing accurate or not?” What actually happened here? In this video, somebody announced a new product. So that’s all information that is interconnected and if you can connect all of these things together to form a higher level of understanding, that’s really knowledge.
chris.eth | GraphOps: Why are graph structures better suited for finding LLM context vs. vector stores or relational stores (given all the SQL in training data)?
Yaniv: Good question. Definitely you want vector embeddings as well, and so it’s for different parts of the problem. So Neo4j supports embeddings and you need that for LLMs, but the reason is you really want a way to precisely get the most relevant knowledge and you want that knowledge to be up to date, and graph queries are the best way to do that. The problem with the relational model is that it implies that you know the structure of things upfront, and the reality is that as you’re building applications, even within a single application, the schemas are often evolving. You realize you need another field to support this new use case, or actually, this thing is related to that thing, so we need to add it. That’s within a single application, but imagine that you have a thousand applications that are touching the same courses and lessons because there are all these different ways that you want to build customized educational apps or whatever it is. The structure of things is constantly evolving so a relational database is never going to account for the dynamism of things constantly evolving, so that’s why graphs are powerful.
chris.eth | GraphOps: How does public and private (e.g., gated institutional) knowledge interoperate on the knowledge graph?
Yaniv: This is something we’re building as part of the framework. I’m really excited about this. I think it’s going to be game-changing. For the first time, we’re looking at how to support private, shared, and public knowledge and information because I think if you’re building applications, it’s actually rare that an application only deals with public information. Maybe we could say that in DeFi a lot of the stuff has so far been public, it’s all on chain, but for generalized applications, maybe there’s a publishing step or a point where you make something public: here’s a video, here’s a post. But a lot of times, you’re working privately or with a team or family. So in order to enable web3, you actually need to be able to build applications that cross those boundaries. You’re empowering the user, they’re performing some actions, maybe it’s with private knowledge and information or maybe they’re sharing it with their team, and then they’re selectively publishing some of that. The knowledge graph structure can encompass all of that because spaces can reference knowledge and entities across different spaces. It’s just a question of whether the space is public or private, and if it’s private, you can encrypt it and make it truly private, keeping it on the user’s local device. When people talk about web3, they talk about this kind of stuff, and I don’t think this vision has been realized yet and I think we’re going to be the ones that make it happen.
chris.eth | GraphOps: How does the knowledge graph prevent GUID collisions? First come, first serve + subsequent permission enforcement by the kg-node indexer?
Yaniv: This was one that, in the early days, took me a while to wrap my head around. Basically what this comes down to is governance. You can have personal and private spaces that are untrusted and you can publish any kind of garbage that you want into your own personal space, so that could include terrible knowledge and information, obscene things, or ID clashes. Public spaces don’t have to include you as part of their public spaces, so if you have ID clashes because you have a malicious UI or user or something like that, it’s up to the governance of the public spaces to filter that stuff out and to enforce quality. Any client that is not acting maliciously should be able to avoid collisions and then it’s up to public governance to include spaces that are behaving properly.
chris.eth | GraphOps: How do you see the discovery and adoption process for attributes? What are new barriers for an adopter to adopt an existing attribute (e.g., write perms via governance)? How to prevent attribute fragmentation by each new user? (e.g., my birthday attribute vs. your birthday attribute)
Yaniv: Great question. This is where really interesting stuff comes up when you’re thinking about how we’re going to build these web3 apps. That’s for sure core to this, and part of what we want to do, and that knowledge graphs are uniquely suited to do, is to balance full freedom and customization with reuse and composability. In some ways, you could say those things are kind of intention because if everybody’s just going to do their own thing, then you’re not actually going to get much reuse or composability. So you want to make it easy to reuse and share things, but then if there’s a valid reason for people to be like, no, what I’m doing is different, we give them the freedom to customize and to just change the things that they want to be different, so they’re still getting maximum composability and reusability, but they can just tweak things the way they want. A lot of that comes down to the developer tooling, so you could imagine that I’m going to build a news app and there’s already a news story out there, there are already these base types, so you want to make discovery of those types easy: here are public spaces and other things people are building. Your first step will be to pick the existing things that are closest to what I want and I’ll just reuse those. One thing that’s really awesome about the knowledge graph type system that’s different from your traditional type systems is the way that the attributes are decoupled from the types. So I can use an existing type and add my own attributes to it; it’s not all or nothing. With proper tooling, it should be easy to maximize reuse.
stake-machine.eth: Who is responsible for content moderation? Can we build a web3 Wikipedia with it?
Yaniv: Great questions. For moderation, it kind of comes down to the spaces. I would read the governing public knowledge post because it addresses this question. I call the concept limits and maybe there are some limits that should be enforced across the global graph, that’s an interesting question, but ultimately each space can define its own values and principles. From a philosophical level, this is something that we’re introducing a little bit because it’s hard to know with web3: what are we doing that are tools for individualism and that are tools for coordination? You want a balance of both. You have the freedom to create your own space and you can do whatever you want and other people can’t tell you what to do. I think that’s important and we want to support that. Obviously, different jurisdictions have laws and if you’re breaking the law in your country, law enforcement might show up at your door, we’re not going to stop that. Ultimately, these are interesting questions and what we want to do is empower communities to… part of coordination is being able to define your own values, beliefs, principles, and policies, and then within your space you should be able to enforce those. That way, people who have the same beliefs can work together. We’re providing tools for communities to do that.
You could build a Wikipedia on this; sometimes people look at Geo and they think that it’s kind of Wikipedia-like. I think it’s much more than Wikipedia. Wikipedia is a starting point but it’s for mostly objective information and mostly static. Most interesting information, a lot of it is subjective and it’s dynamic. Most X posts aren’t making it onto Wikipedia, but they should all be part of the knowledge graph. Anytime someone publishes something, that should be part of the knowledge graph. Reddit, same thing, the comments and the conversations that are happening should be part of the knowledge graph. Markets, products and services, and basically every application should be part of the knowledge graph, so it’s much bigger than Wikipedia, but you could use that as a starting point.
Jim | Wavefive: Where does truth fit into that though, Yaniv, because what you’ve just described is sort of like the formalization or the crystallization of infinite realities, which is where we are today where there’s no such thing as truth, almost.
Yaniv: Yeah, this is a very deep topic, and it’s really the subject of this post, so please, everybody, make sure you read this governing public knowledge post. It lays the foundation for understanding that question, and I think it’s the biggest question of our time. I think some people are almost afraid to tackle it because it’s such a big question, but I actually think it’s the single largest problem that humanity has today, it’s the biggest problem of our time, and if The Graph solves this problem… if you solve the biggest problem of the time, I think you build the most valuable thing, and I really think The Graph can be the most valuable thing. It’s why I’ve dedicated my life to it. You need to have the right foundation, and this post goes into it. It starts with how you structure knowledge and information. You can’t just represent facts, and then everyone’s like, yes, that’s a fact, no, that’s not a fact, and then you’re screaming past each other. So you have to structure the information in a way that’s correct, even if there’s disagreement. If you have things like claims, someone can make a claim, that doesn’t mean that it’s true, and then you can structure things like supporting arguments and opposing arguments, you can observe who supports which claims. So you have these spaces, and each space should be able to get to consensus on its own, now again, if you force everyone to agree on everything, you shouldn’t even get a single space to consensus, but if you structure things in a flexible enough way, then you can get a group of people with shared beliefs to agree on a state of the world and agree with how we’re doing this. Then the question becomes can you organize these spaces into larger and larger configurations that represent, essentially, global consensus. Now, global consensus does not mean truth. The consensus is often wrong. But what you want is to give groups the ability to represent knowledge to the best of their ability and then interconnect that into larger and larger communities. You want to have a system that converges toward truth.
Essentially, that’s what this is, it’s a generalized system, where if you build a system, it doesn’t mean that the system is always correct, but if the design of the system is correct, then you know that it’s by definition the best that you can do, people can trust the system, and you can trust that it’s self-healing and improving over time. I think that’s what we can build here.
Final words from Yaniv [1:15:41]
We’ve been working on this for a very long time, and it’s now ready and we’re going to be rolling it out in a few different stages. What I’d love to see is collaboration across participants, across core devs, which I think in some ways will look a bit different than what we’ve done before. But I think the opportunity is so much greater.
We don’t want to think of ourselves as purely an indexing and query protocol because there are hundreds of services out there for querying blockchain data, and if that’s all we are, we’re one of a hundred, we’re one of a thousand. We can be slightly better, but we’re talking marginal improvements. The indexing is a core part of what we’re talking about here, the same way that Google does so much more than indexing, but they’re viewed as indexing. It’s an important part of the stack, and the fact that we do indexing better than anyone else is going to be a huge competitive advantage. But we don’t want to be a commodity, and so the way that we move beyond just being a commodity is we tackle the biggest problems of our time and we do things that are really important, that are going to change society, and that are going to make the world a better place using these tools.
That was the idea for The Graph from the beginning. Everything is knowledge and information, and if we can build the global graph of all of the world’s public knowledge and information, organized and served in a decentralized way, for me, that is The Graph and I believe that is also the most valuable thing that can exist.
How do we get there? Let’s focus on these two goals: 1) more useful knowledge and information better organized and 2) enabling interoperable consumer apps. If we focus on these North Stars in the short term, then we need a bit of a zero to one moment to really get this web3 thing kickstarted but that’s basically what we’re going to be doing at the beginning of the year. I would love to have more people working together, let’s collaborate, let’s do such a great job with this that we really make web3 incredible, we get it out into the world, we grow extremely rapidly, and we make the world the vibrant decentralized place that we want it to be.





No Comments