


Last Updated on August 13, 2024 by Pinax Team
TL;DR: Participants focused on optimizing PostgreSQL databases for performance and scalability, discussing sharding, indexing, monitoring, and diagnosing slow queries, with plans for detailed future workshops.
Opening remarks
Hello everyone, and welcome to episode 169 of Indexer Office Hours!
GRTiQ 180
Catch the GRTiQ Podcast with Aki Balogh, Co-Founder and CEO at DLC.Link, a platform that facilitates trust-minimized Bitcoin smart contracts and DeFi applications using Discreet Log Contracts (DLCs). Aki discusses his tech journey, meeting Bill Gates, founding MarketMuse, and transforming DeFi with DLC.Link.
Repo watch
The latest updates to important repositories
Execution Layer Clients
- Erigon New release:
- v3.0.0-alpha2
- Key features in alpha2 focus on initial sync: Erigon becomes “Evergreen,” allowing the download of the latest files even if not using the latest version, with releases near the chain-tip (10K-100K blocks); alpha3 will focus on chain-tip performance and peak RAM usage.
- v3.0.0-alpha2
- Nethermind: New release v1.28.0-rc
- Introduced the eth_simulate RPC for advanced block simulation, enhanced Optimism support including the ability to function as a Sequencer, and implemented numerous performance optimizations and bug fixes.
Launchpad Stack
- Launchpad-charts:
- New chart versions released with enhanced features and bug fixes:
- Erigon, Arbitrum-Nitro, Nimbus, Graph-Network-Indexer
- Proxyd: consensus_aware boolean config has been replaced by a new parameter routing_strategy
- Subgraph-Availability-Oracle: support for custom labels and updated dashboard
- New chart versions released with enhanced features and bug fixes:
- Posted in Chat – Matthew Darwin | Pinax: “New proxy” – https://docs.erpc.cloud/ which is fault-tolerant EVM RPC load balancer with reorg-aware permanent caching and auto-discovery of node providers
- Launchpad-namespaces:
- New stable versions of Ethereum, Gnosis, Polygon, Arbitrum, Celo, Monitoring, Ingress
- Launchpad Charts Issues: View or report issues
- Launchpad Namespaces Issues: View or report issues
- Key features in alpha2 focus on initial sync: Erigon becomes “Evergreen,” allowing the download of the latest files even if not using the latest version, with releases near the chain-tip (10K-100K blocks); alpha3 will focus on chain-tip performance and peak RAM usage.
Protocol watch
No new updates since last IOH. However, [Timestamp 7:17] paka | E&N stated he will be attending the Builder’s Office Hours to discuss subgraph enhancements.
Open discussion [Timestamp 7:46]
Open discussion on Postgres Sharding Strategies: It was noted by the host AbelsAbstracts.eth | GraphOps there will be a Postgres workshop happening on the 27th of August.
In the chat Vince | Nodeify states he’s been playing with zalando/postgres-operator and also stake-machine.eth posted a link he’s using vitabaks/postgresql_cluster
- Jim’s (Jim | Wavefive): He first explains is building a new horizontally scalable graph stack to replace his monolithic database system.
- Jim is concerned about effectively transitioning to a sharded database architecture and optimizing Postgres performance to handle resource-intensive subgraphs and slow queries. He seeks practical strategies, monitoring tools, and best practices for database indexing and caching. Jim’s main questions can be listed when paraphrased.
- What sharding strategies work best for scaling?
- Answer: [Timestamp 30:03] So what we do is we have one primary which should only have the metadata… and then all the other ones are just subgraphs… for the most part, yeah, there’s no really great strategy so we basically put subgraphs round-robin into those shards except for a couple things where we know we’re getting a lot of query traffic.” lutter David Lutterkort
- Answer: [Timestamp 35:31] “Use of Grafana dashboards to monitor active queries via PG Stat Activity and PG Stat Statements… Google Cloud monitoring tools.” lutter David Lutterkort
- Answer: [Timestamp 24:15] “That’s where looking at that query and adding an index can have a huge impact… I’ve seen cases where a database shard is at almost 100% utilization, you add an index and it drops to 40%, just by having one index.” lutter David Lutterkort.
- Answer: [Timestamp 35:31] “Use of Grafana dashboards to monitor active queries via PG Stat Activity and PG Stat Statements… Google Cloud monitoring tools.” lutter David Lutterkort
- Answer: [Timestamp 30:02] “If you see that a specific subgraph gets like 20-30% of the queries and The Shard it’s in is under a lot of stress, I would set up a dedicated shard for that or maybe put a few subgraphs in there.” lutter David Lutterkort.
- Answer: [Timestamp 25:03] “Initially, indexes are created on every attribute of every entity… Once a subgraph has gotten a certain number of queries, there’s ways to see which indexes are actually used and dropping indexes can help a lot in lowering the write load.” lutter David Lutterkort.
- Answer: [Timestamp 27:11] “Graph node has some caching built in… The gateway doesn’t cache but graph node does.” lutter David Lutterkort. Lutter later posted in chat.
- Cashing Gist: This explains two things: how to get a trace for a GraphQL query and all the different settings that affect the cache inside graph-node.
- Answer: [Timestamp 30:45] “The primary database should hold only metadata… separate shards for block caches… and distributing subgraphs round-robin into other shards.” lutter David Lutterkort.
- Suggestion: Payne | Stake🦑Squid “isn’t Pinax running a Arb Sepolia node you can hit? You would still need a caching layer. “
- Answer: Matthew Darwin | Pinax: “you can use the Pinax RPC for testing.”
- Can graphman can be used to reorganize a database for better efficiency?
- Answer: [Timestamp 31:24] Lutter confirms, explaining how graphman copy can duplicate and reassign subgraphs.
- What sharding strategies work best for scaling?
Comments in the chat:
Vincent | Data Nexus: Issues related to implementing the views so that it wouldn’t be as big of a PITA to implement sharded status dashboards https://github.com/graphprotocol/graph-node/issues/4825https://github.com/graphprotocol/graph-node/issues/4824
Jim | Wavefive posted delayed queries he’s had:
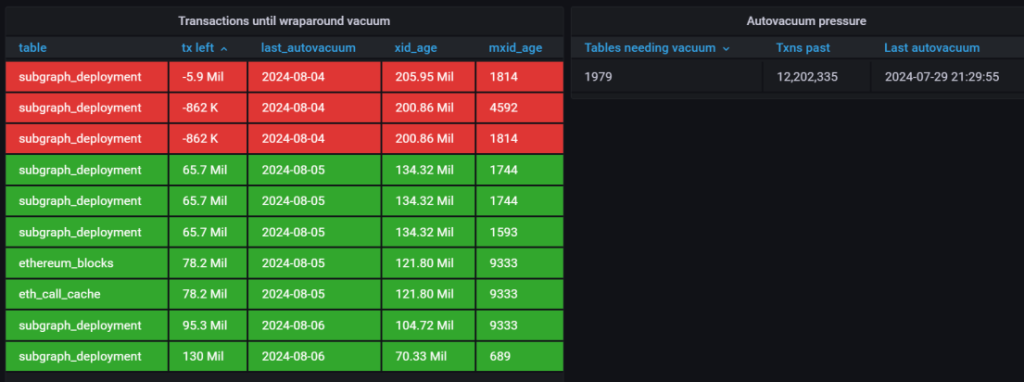
Question: Stake-machine.eth: does graph-node cache it in psql?
- Answer by Ford: graph-node has it’s own in-memory cache that keeps repeat queries from making it to the DB
Question: Stake-machine.eth: so for query-node it’s better to have more RAM, but can index-node utilise cache in any way?
- Answer by Ford: Query cache is just for graphQL queries, so not useful for index-nodes. Yeah, very RAM dependent, and there are some configs that can be used to tune the cache.
Question: Stake-machine.eth: and any plans to add caching to indexer-service?
- Answer by Ford: not at the moment, keeping indexer-service as light as possible. Simply pass through of queries and handling payments.
Question: Stake-machine.eth: can we offload some load to nginx cache?
- Answer by Ford: I’d think that’d be very tricky to also handle payments if you try to use an NGINX cache in front of everything.
General comment: Mickey | E&N In the workshop, John may also plug a new idea that he’s exploring for E&N using a Citus cluster that you all might benefit from. Citus info here: https://docs.citusdata.com/en/v11.1/get_started/what_is_citus.html





No Comments