


TL;DR: In this recap of IOH #163, a member of the Scroll team joins to introduce the network and answer questions, plus there’s a discussion on indexer quality-of-life improvements.
Opening remarks
Hello everyone, and welcome to episode 163 of Indexer Office Hours!
GRTiQ 174
Don’t miss the GRTiQ Podcast with John Paller, Founder and Steward at ETHDenver, and Founder of Opolis.
Repo watch
The latest updates to important repositories
Execution Layer Clients
- sfeth/fireeth: New release v2.6.3 :
- Fixes “hub” not recovering on certain disconnections in relayer/firehose/substreams (scenarios requiring full restart).
- Nethermind: New release v1.27.0 :
- One of the key advancements in this release is the implementation of an intra-block cache. This optimizes the processing of transactions within blocks, resulting in the system’s ability to avoid recalculating the state for transactions within the same block. This not only reduces redundant computations but also accelerates block execution, leading to a notable boost in overall performance.
- Add native prestate tracer.
- Add native call tracer.
- Implement intra-block cache.
- Pre-warm intra-block cache during block execution.
- Feature external signer.
Consensus Layer Clients
Information on the different clients
- Teku: New releases:
- v24.6.0 :
- Breaking change: renamed -Xp2p-dumps-to-file-enabled hidden CLI option to -Xdebug-data-dumping-enabled .
- This is a recommended update with performance improvements and bug fixes.
- 24.6.1 :
- Fixes an issue from version 24.6.0 where Teku failed to start on machines with directly assigned public IP addresses (not running under NAT), displaying the error message: Teku failed to start: java.io.UncheckedIOException: java.net.UnknownHostException: Unable to determine local IPvx Address .
- v24.6.0 :
- Nimbus: New release v24.6.0 :
- Nimbus v24.6.0 is a low-urgency release with performance and safety improvements.
- Fixes light client libp2p gossip topic subscriptions.
- Improves SHA256 protocol object hashing speed by 30%.
Graph Stack
- Graph Node: New release v0.35.1 :
- Declarative eth calls: supports executing eth calls ahead of time and in parallel. Using this feature, the time for all calls goes from the sum of the time the calls take to the max.
- Support for differentiating EOA from smart contract accounts: ethereum.getCode can be used in mappings to check whether smart contract code is present at a given address.
- Support additional event filters: allows filtering on indexed arguments.
- Aggregations now use Timestamp type for the timestamp attribute.
- Refactor manual index creation and adds ddl tests.
- Refactor graphman rewind to use pause and resume logic.
- Add deployment ID to Firehose connection headers.
- Improve the Ethereum Firehose codec.
- Fix static filters restart behavior when using threshold.
- Try to be more consistent in Firehose parsing to address.
- Include ‘provider’ in various Firehose log messages.
- Do not send all Firehose headers when its init triggers only.
Graph Orchestration Tooling
Join us every other Wednesday at 5 PM UTC for Launchpad Office Hours and get the latest updates on running Launchpad.
The next one is on July 3. Bring all your questions!
Protocol watch
The latest updates on important changes to the protocol
Forum Governance
edeXa, BEVM, and peaq are EVM-compatible chains; Injective is Firehose.
Contracts Repository
- ❄️ Graph Horizon and Subgraph Service ❄️ #944 (open)
- Subgraph Service: unit tests #986 (open)
- feat: subgraph availability manager contract #882 (open)
- chore: SAM deployments #961 (merged)
- chore: deploy SAO data edge and add missing addresses #964 (merged)
Project watch
A reminder to indexers: if you’re using hosted service endpoints for your infrastructure, update your network configurations to the decentralized network.
Updated docs for network configurations:
Open discussion
Scroll presentation (Timestamp 9:22)
Isabelle Wei, an integrations engineer from Scroll, joined to introduce the network and answer questions. Scroll has integrated with The Graph Network and has full protocol support.
- Presentation slides
- Indexer Guide
- TG: @isabellewei
Intro to Scroll
At its roots, Scroll is a research team interested in ZK technology.
The Scalability Trilemma
For any distributed technology, there are three main items that you can focus on: scalability, decentralization, and security.
Ethereum has focused on decentralization and security at the expense of scalability (e.g., high gas fees). This approach is not very sustainable or accessible to everyone, which is why rollups like Scroll are valuable.
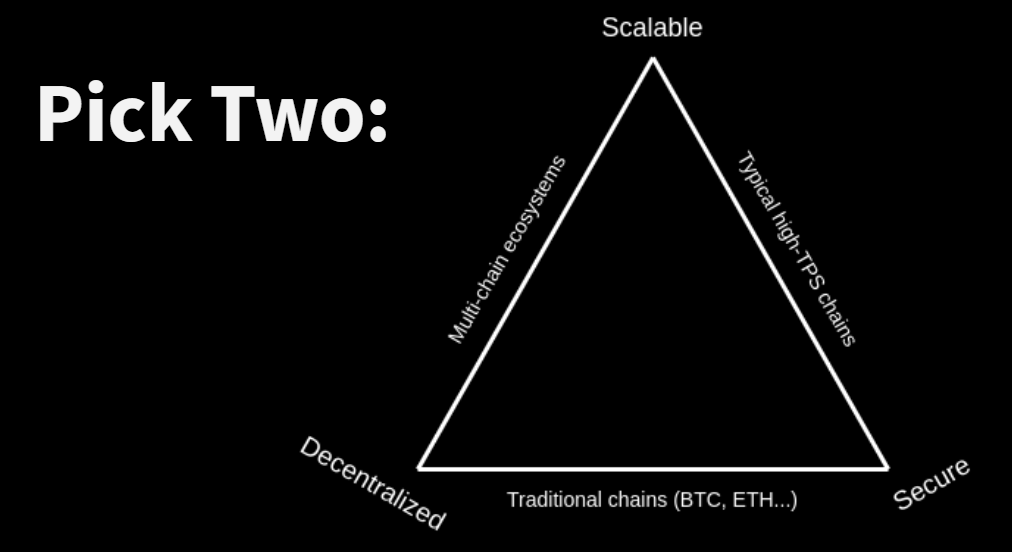
Scroll is a Layer 2 network for scaling Ethereum through zero-knowledge proofs.
In the ecosystem of rollups, Scroll believes ZK is the endgame of scalability. It’s totally trustless, you can verify information easily, and the finality time is short compared to other Layer 2 solutions.
Scroll’s goal is to make building on Scroll as easy as possible by striving to have parity with Ethereum as much as possible.
The team has implemented upgrades to introduce new op codes and the UX is simple.
“Anything you can do on Ethereum… but cheaper and faster with a higher throughput.”
Running a Scroll node
Scroll RPC nodes
- A fork of Geth
- Uses Clique protocol for consensus
If you have experience running Geth nodes, running a Scroll node is similar (e.g., same CLI, APIs, namespaces).
- Guide: Running a Scroll L2geth Node
- Running a Scroll L2geth Node from Snapshot (Scroll Mainnet)
- Third-party RPC providers: QuickNode, Ankr, Chainstack, Blast API
- For running a private node—make sure you get an archive node that is not rate limited.
- Scroll RPC Namespace Guide
- For custom APIs, likely not needed for indexer-related tasks.
Tooling
The team is currently migrating the system to Kubernetes, which makes it easy to scale up and down and take advantage of Kubernetes cluster features.
They use Prometheus and Grafana for metrics and analytics.
Occasionally, they use Pyroscope for debugging.
- Status page
- “node-support” channel on Discord (will be linked on The Graph Discord soon)
- Scroll support request form
Scroll Q&A
Do you have Scroll archive node snapshots available to download?
- Yes, snapshots are available for mainnet now, and we’re working on making snapshots for Sepolia testnet available. See the link above for “Running a Scroll L2geth Node from Snapshot (Scroll Mainnet).”
How often are new snapshots published?
- Every two weeks.
Did you say it is possible to enable tracing with the current Geth implementation or is Ankr using some in-house solution for tracing?
- There are Trace APIs under the debug namespace that you can enable on your Geth node. Ankr has them enabled.
Is the Scroll Discord going to be linked to The Graph Discord?
- We’re working on that for some chains, including Scroll.
Any tips for maintaining a healthy peer count? It was challenging as of a couple of months ago.
- The best thing to do is probably try to connect directly to one of our boot nodes, which we list publicly in our docs.
- We don’t really whitelist because we have a couple of boot nodes that we save for our main RPC providers. For Sepolia, the boot nodes are public so you don’t need to be whitelisted.
- If you’re having trouble connecting to peers, we’ll look into it and see where the issue is.
Feedback:
- Marc-André | Ellipfra: I cannot access the 2 boot nodes listed in the doc: the TCP port is closed.
- If you want proper support by The Graph Network, please ensure indexers have prime access to the network. The fact that you need to whitelist access is not a good thing.
Is there any plan to merge the scroll(geth) to upstream(go-ethereum)?
- We periodically merge upstream updates from Geth, on a needs-basis if we get demand from projects for a certain function. In the past, we’ve had community members create PRs, and we will include them if reasonable. There’s no specific roadmap, but we will merge upstream as we see fit.
Is there a plan for Reth or Erigon?
- Our engineering team wants to implement Reth. We actually have a team member who worked on the original Reth. The timeline will depend on resources and priorities.
Indexer community discussion (Timestamp 32:35)
Indexer agent
Vince | Nodeify: Is there an update on indexer agent release support for other networks?
Ford: We’re trying to get a bunch of in-flight PRs in:
- Resolving TAP subgraph stuff
- Fixing the pagination of subgraphs where some were getting missed
- Adding support for new chains
Hopefully, we’ll get a release out sometime this week (June 24–28).
Indexer quality-of-life improvements
Vincent | Data Nexus: I would like to shout out my current short-term wishlist for indexer QoL improvements, which are sorely needed now that subgraphs and allocations need to be managed more actively.
- [agent] Give control of initial deployments to graph-node’s deployment rules
- [agent] Give control of subgraph deployment name to indexer-cli
- [agent] Auto grafting management
- [agent] Local deployments with backup query URL for all subgraphs required for service (graph network, EBO, and soon to be TAP)
- [graph-node] Make call cache a config option for indexers with locally hosted RPC nodes
Ford: Most of those are works in progress!
In the EBO config, you can definitely supply a URL and a deployment separately. I’ll double check and make sure we’re using the same kind of fallback and freshness logic on that. Is your experience showing otherwise?
Chris | GraphOps: By my memory, I’m not sure that you can pass a deployment hash for the EBO. I think you can only specify an endpoint.
Ford: I don’t think that’s the case. I’m thinking of the network config file method where you have a YAML file and a subgraph section, underneath that you can supply network subgraph and epoch subgraph, and for both you can supply URL and deployment, but maybe you can’t do that if you’re following the startup param way or the environment variable way.
Thanks for the callout. We can check that, and if it’s not like that already, we can improve it.
Someone already made an issue for this: Enable EBO subgraph endpoint to fail-over to network if locally synced version unavailable #925
Ford: To clarify the call cache request, do you want to have the option to turn that off and not use a call cache at all and instead say always go to my RPC node?
Vincent | Data Nexus: Yes, exactly.
Ford: What is driving that request?
Vincent | Data Nexus: It would be helpful for indexers that use local nodes and are running low on storage space.
Ford: There’s a new feature in Graph Node, declarative eth calls, which allows you to specify the eth calls you’re going to make in your mappings, but specify them in your manifest, and then Graph Node will resolve those ahead of time, out of band in parallel so they don’t block your subgraph syncing. I think that’ll dump them to the call cache right now, but I’m thinking ahead to a case where, with declarative eth calls, a call cache is less important and most indexers could turn it off.
Derek | Data Nexus: Won’t declarative calls dump the results into the cache? Maybe have some type of TTL in there. It’d be really nice to have a synced_at column so we can benchmark more easily.
Ford: Yes! 1000%. something like that to make sync metrics more consistent.
Vincent | Data Nexus: Also, on point 2 here ([agent] Give control of subgraph deployment name to indexer-cli), I ended up hacking together an implementation if you’re interested in seeing exactly the kind of behavior I’d like in order to work well with the graph-node deployment rules. I’d really like to be able to easily deploy VIP subgraphs to VIP databases from the start, instead of syncing on the default and copying to the VIP db.
feat: Deployment tags to replace indexer-agent prefix in deployment names #921
Ford: I can see how being able to add custom names in combination with using the deployment rules could make it easier to set up your user-specific or VIP clusters and shards.





No Comments