


TL;DR: Matthew from Pinax presented on scaling Substreams, explaining how to set up and monitor tier 1 and tier 2 nodes for processing blockchain data. The architecture involves tier 1 nodes that are chain-specific and tier 2 nodes that are blockchain-agnostic. The setup requires monitoring through Prometheus and Grafana, with proper hardware sizing depending on specific Substreams workloads and complexity. While Kubernetes is ideal for scaling, the system can work without it, and older hardware can be effectively utilized as long as there's sufficient CPU and RAM.
Opening remarks
Hello everyone, and welcome to episode 192 of Indexer Office Hours!
GRTiQ 205
Catch the GRTiQ Podcast with Brianna Migliaccio, Developer Relations at Solana. At Solana, Brianna works to empower developers, helping teams leverage Solana’s speed and scalability.
⬇️ Skip straight to the open discussion ⬇️
Repo watch
The latest updates to important repositories
Execution Layer Clients
- sfeth/fireeth: New release v2.9.3 :
- Date: 2025-01-21 20:18:46 UTC
- Updated the fireeth tools geth enforce-peers command: -o is now deprecated and should be replaced with –once. This change impacts command syntax but not overall system security or functionality.
- Urgency indicator: Yellow
- Urgency reason: Important command syntax change, not critical.
- Arbitrum-nitro New release v3.4.0 :
- Date: 2025-01-23 21:30:35 UTC
- The release includes critical bug fixes, performance improvements, and new features such as support for ‘genesis.json’ initialization. It also removes the ‘–node.inbox-reader.hard-reorg’ configuration and fixes important issues like the execution gas cap. Operators should review the update for important changes that could affect system performance and configuration.
- Urgency indicator: Yellow
- Urgency reason: Important fixes and performance improvements.
Consensus Layer Clients
Information on the different clients
- Teku: New release v25.1.0 :
- Date: 2025-01-22 08:08:24 UTC
- Version 25.1.0 includes breaking changes to CLI options and metric naming conventions, which may affect existing configurations. There are performance improvements and bug fixes, but no critical security issues or immediate operational impacts.
- Urgency indicator: Yellow
- Urgency reason: Important changes; require configuration updates.
Protocol watch
The latest updates on important changes to the protocol
Forum Governance
- Chain Integrations Tracking Doc
- The guide for X Layer has been added.
Contracts Repository
Most of the PRs are related to Horizon deployment, as well as adding some scripts to migrate protocol contracts and potential changes to the Horizon contract codebase.
To view all the PRs, refer to the Indexer Office Hours #192 Agenda.
Network Subgraphs
- Epoch Block Oracle subgraph: Fixes to ChangePermissions message encoding/decoding (v0.2.1, PR)
Open discussion [7:32]
Scaling Substreams with Matthew from Pinax
- Presentation slides – slide content appears first in each section, with more details added from Matthew underneath.
Matthew | Pinax: The way to scale Substreams has changed and become easier in the last year, so this is a good time to talk about it.
Here’s the original architecture diagram of where Firehose fits in for anybody new to this.
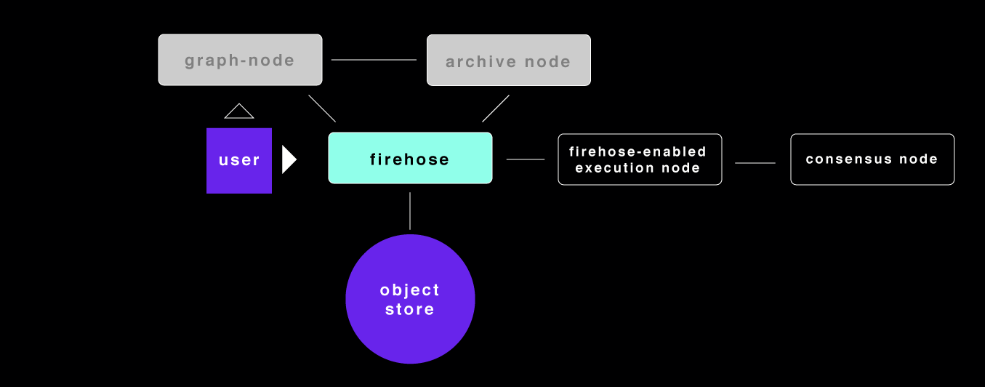
We have graph-node that normally talks to archive node, and here we’ve introduced Firehose, which needs some sort of Firehose-enabled execution client, or there’s a new mode where Firehose uses RPC calls, so it could actually use the same archive node. The items on the right are optional depending on the chain.
Let’s zoom in. The details of all the Firehose components are shown in this diagram. Today, I’m going to focus on the Substreams parts: Substreams tier 1 and Substreams tier 2.
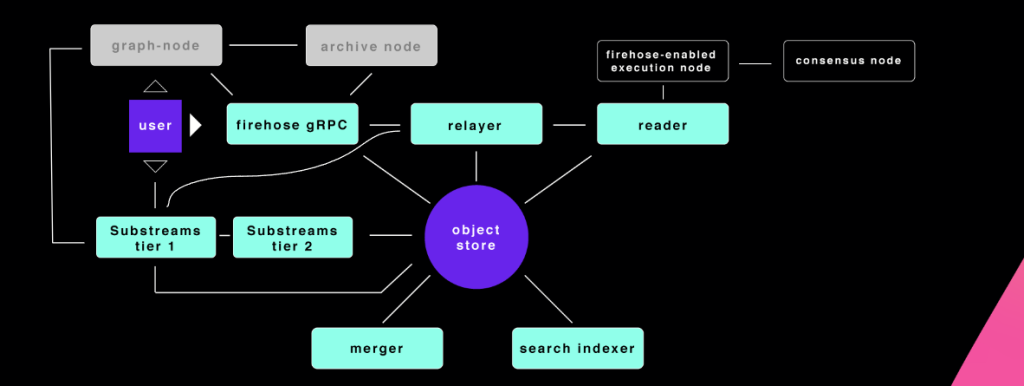
What are these Substreams components?
Substreams tier 1
- End-user-facing gRPC endpoint, processing live data
- One (or more) per chain
- Scale according to workload
- Run the specific Firehose binary for the chain or firehose-core if none
With more detail from Matthew
Substreams tier 1 is user-facing or graph-node facing.
Tier 1 is the end-user-facing component that is processing live data. In the diagram, you can see Substreams tier 1 is connected to the user. The user can connect directly to Substreams tier 1 or graph-node can connect to Substreams tier 1. If you’ve got a Substreams-powered subgraph and you configure Substreams in the graph TOML file, graph-node can connect to Substreams as well. Graph-node can read from an archive node doing RPC calls, from Firehose, and from Substreams, so there are multiple ways of getting data into graph-node.
You need one or more tier 1 per chain and more for scaling. If you want to do an Ethereum Substreams-powered subgraph, you’re going to need at least one Substreams tier 1 node.
When we’ve talked about Firehose in the past, we always gave just one stack. You can run all the Firehose components in the diagram above. Everything can run in one binary. You can still do that, but today’s presentation is about scaling.
You can’t just scale one, right? If we’re talking about scaling, we’re talking about bringing Substreams tier 1 and tier 2 to multiple machines. Specifically, we’re talking about horizontal scaling, meaning to scale across multiple servers.
You need at least one Substreams tier 1 node and more if you have Substreams-powered subgraphs. I don’t know what the number is before you need more—you’d have to look at your hardware as it’s according to the workload.
If you have different chains that you want to support, you need a Substreams tier 1 endpoint for each chain, just like you need a Firehose for each chain. So you need a Substreams for Ethereum, you need one for BSC, you need one for Polygon, etc.
Then you run the specific Firehose binary for the chain or Firehose Core if it’s for Solana, for example.
It’s the normal setup that you would do with the rest of the Firehose stack. Substreams tier 1 looks pretty much like that.
Substreams tier 2
- Historical blocks processing node, blockchain-agnostic
- Blockchain-agnostic: one node can process data from many chains at once
- Always run fireeth (firehose-ethereum), even for non-Ethereum chains
With more detail from Matthew
Substreams tier 2 is very different.
You can run it like tier 1, and you can assign one tier 2 node to each tier 1 if you want, but that doesn’t scale very well because of the load that Substreams needs to process. At one point, it needs to process a new subgraph on Ethereum, so it needs a bunch of tier 2 nodes to quickly process that, it catches up to live, and then those tier 2 nodes are sitting there with nothing to do. But then you start syncing a subgraph for BSC, and now those tier 2 nodes can be busy again.
So if you have one pool of tier 2 nodes that can be shared across Ethereum, BSC, Polygon, Solana, name whatever chain you want, you only need one cluster of tier 2 nodes. If you want one cluster per blockchain, go ahead, but the thing that changed in the last year is that now you can create one tier 2 cluster and have it hooked up to all your tier 1s, no matter what the blockchain. This makes it much easier from a scaling perspective.
Substreams tier 2 is responsible for processing the historical blocks. In a parallel mode, the jobs are split up and then we can process them, and it’s blockchain-agnostic.
Interestingly, you run Firehose Ethereum on your tier 2, so if you want to share, even for Solana, Bitcoin, NEAR, Arweave, or any other non-Ethereum chain, you still use Firehose Ethereum. This is because Firehose Ethereum has the most features of all the blockchains, so with Firehose Ethereum you can support any other blockchain.
Substreams storage [14:47]
- If you want to scale Substreams, you need to be using object storage
- (when not scaling, it is fine to write to local file system)
- We use S3 buckets in Ceph
- SeaweedFS S3 is also known to work
- Need space to store Substreams cache
- There is no out-of-box automated clean-up process for Substreams cache files
- No local storage needed for Substreams
With more detail from Matthew
Previously, when we talked about Firehose, we talked about how you can store your Firehose blocks locally on a local disk or you can put them in an S3 bucket. If we’re talking about scaling, now you need to put them in an S3 bucket or some kind of object storage because you’re going to have to share those Firehose blocks across multiple machines as your Substreams nodes scale across more machines.
At Pinax, we use Ceph and other people have used SeaweedFS. Your mileage may vary depending on what you try. Other people also store in Google Cloud or you can start in AWS—those are expensive, but it’s good to try different things. If you want advice on what to try, ask questions in the Discord channel.
Really, you need some sort of object storage. For ease of use, figure out how to run an object storage solution.
I see Vince is sharing that Hetzner also has object storage. Excellent. You can get object storage on DigitalOcean as well (it uses Ceph behind the scenes).
Vince | Nodeify: If you’re in the EU, Hetzner has buckets, and it’s so cheap it fell off a truck.
In addition to the Firehose blocks that you may already have, you need space to store the Substreams cache. So Substreams, when data gets processed, ideally, if nothing changes, you don’t want to process again, so the results for all the Substreams calculations are stored on disk, in S3 storage, or in your object storage, so you need space for this.
You can clean up those cache files if there’s a subgraph you synced, and six months later, nobody’s using that subgraph anymore. If it’s obsolete, you can delete the cache files for it. There is no automated out-of-the-box Substreams cache clean-up tool. Maybe we’ll think about how to build such a thing or tell you which things haven’t been used recently, but there is currently nothing that comes with Substreams to clean this up. If you accidentally delete Substreams caches that are still needed, the system is going to regenerate them.
Otherwise, you don’t need any local storage for Substreams. It uses the object storage, so when it starts, it pulls Firehose blocks from the object storage and then writes Substreams cache files back to the object storage.
Configuration: tier1 —> tier2 [17:50]
- Tier1 needs to send load to tier2
- Work is split in chunks
- Chunks are ranges of blocks
- Chunks are 1 or more Substreams modules
- E.g. “module1 block 0000=>1000”
- Tier2 writes results back to S3 and informs tier1 that they are ready
- Load needs to be distributed according to tier2 availability
- Each chunk of work is not equal
- (CPU & RAM varies)
- Ways to distribute workload:
- GRPC discovery service (–substreams-tier1-discovery-service-url)
- Health-aware DNS (–substreams-tier1-subrequests-endpoint)
With more detail from Matthew
We need to talk about the configuration: how do we go from tier 1 to tier 2?

Tier 1 needs to send the load to tier 2, so if a user or graph-node connects and says, “please sync this Substreams-powered subgraph,” we need to split up the work into chunks and then ask the tier 2 nodes to process the chunks.
The chunks are ranges of blocks and there are one or more Substreams modules. Splitting things up by blocks makes sense. Substreams are designed to run in parallel, so if you have, say, 100 Substreams tier 2 nodes, if you split your workload up into 100 chunks, each one can get one chunk at a time, and then they’re all busy.
It doesn’t really work like that, it actually splits it up into a block range, so like a thousand blocks. So every time it processes one thousand blocks, it gives out chunks of a thousand blocks, and then when that chunk is done, tier 2 says, “I’m done,” and then tier 1 will send the next chunk of a thousand blocks tier 2 needs to do. But it might not be the next chunk of a thousand that it just finished because there are other tier 2 nodes busy.
Tier 2 nodes are stateless. They receive a request for a job, they process the job, they write the data back to the S3 bucket, and then they say ready and wait for another job. Otherwise, they sit there and do nothing.
Substreams are composed of multiple modules. So a Substreams module follows an ordered graph of work that has dependencies. You can process this independently of that, and then you take those two results and combine them together to produce an output in a simple fashion.
So a Substreams could have one module or a bunch of modules. The work needs to be split up according to the dependency tree graph, and sometimes you can run multiple dependencies together as a module, as a workload, and sometimes they get split up. The work nodes need to be split by module and by block range.
The best way to see what’s going on is to be a user and run the Substreams GUI and it will show you the workload and what it’s processing, and then you get a good idea of how it works. You can get a visual representation of what’s going with Substreams GUI and then pass the subgraph Qm hash and then you can see it executed. It’s IPFS://Qm whatever, and Substreams will read the hash and process it for you.
Tier 1 needs to split up the work and then send it to the tier 2 nodes. Tier 2 nodes are stateless; they just get whatever work they need to do, process it, write the results back to S3, and then wait for the next thing.
A tier 2 node can process multiple things at once; it doesn’t have to do just one. Maybe a tier 2 is a machine with multiple CPUs in it. You don’t want to use just one CPU, you want to use a bunch, so tier 2 nodes can accept multiple jobs at once.
Each set of work is not equal. Jobs will take more or less time depending on what needs doing. A job may need more or less RAM or more or less CPU.
Load needs to be distributed according to tier 2 availability. There are a couple of ways to determine availability:
- GRPC discovery service – you might use this in Kubernetes.
- Health-aware DNS – if you have a DNS server that understands the state of whether the tier 2 can accept jobs or not, then the tier 1 can connect to DNS and only get the DNS endpoints for the ones that are available.
Health-aware DNS using HashiCorp Consul
We’re using Consul, which is an open source tool from HashiCorp. The basic way it works is if you run this curl command, you can see I’m connecting, so local host 9000 in this case is the Substreams tier 2, so run this command on the Substreams tier 2 node and it returns if it’s ready or not. If the tier 2 node is overloaded, it will say no, not ready and you’ll get a false. If it’s ready for more jobs, it will return a true.
$ curl -s <http://localhost:9000/healthz>
{"is_ready":true}
{
"service": {
"name": "substreams-tier2-v1",
"port": 9000,
"checks": [{
"args": ["/usr/bin/check_tier2_http_health"],
"interval": "5s"
}]
}
}
You can use this with a health check built into Consul to check whether you get a true or false back and then report that back to your DNS and then DNS will add and remove that entry from DNS according to whether it’s true or false.
I’m not going to go through how to configure Consul. The documentation for Consul is really good, so you can figure it out yourself.
In this case, you’ll notice I use [“/usr/bin/check_tier2_http_health”]. This is just a little script that parses that JSON and returns an exit code of either zero, one, or two.
- Zero: I’m available
- One: Maybe not
- Two: Definitely not
That’s how Consul knows if the service is available or not.
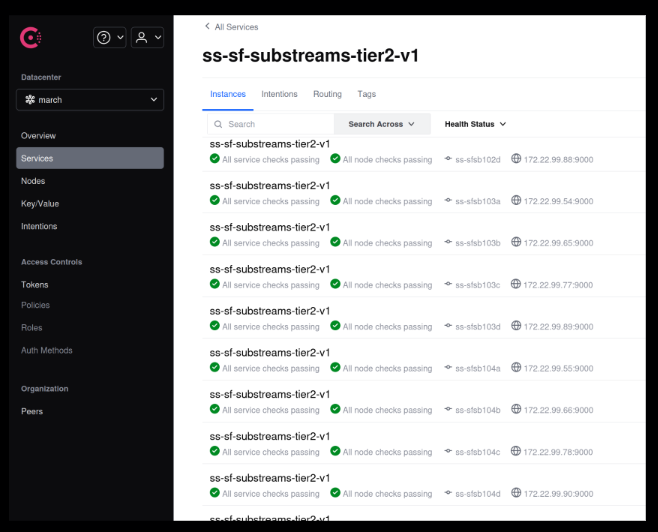
Here’s a screenshot of what Consul looks like in our case. You can see all the nodes and they’re all healthy. If they were not healthy, there would be a red x inside the Consul UI.
Configuration: tier 2
- 128 GiB RAM
- 14 CPU Cores
- How many? As many as you want!
- Chain-specific configuration details are passed from tier1 to tier2
- Do not expose tier2 to public!
start:
args:
- substreams-tier2
flags:
log-verbosity: 0
log-to-file: false
common-auto-mem-limit-percent: 90
substreams-tier2-grpc-listen-addr: :9000
substreams-tier2-max-concurrent-requests: 30
Questions from the chat:
Marc-André | Ellipfra: How does the tier 2 node determine that it is overloaded?
Matthew: How does the tier 2 node know if it’s overloaded or not? You tell the tier 2 node how many jobs you want to process in parallel. So, in this case, if you look at the last line of the code above, I put 30.
substreams-tier2-max-concurrent-requests: 30
You can put whatever number you want there, and then when it gets to that number of jobs that it’s running, it will change the health check to false, it will remove the endpoint from DNS, and then tier 1 will not send jobs to tier 2. If you put it too high, then obviously, you’re going to run RAM or CPU; if you put it too low, then you’re wasting hardware. So the challenge with configuring Substreams is getting a feel for your hardware and the load that you have.
You can fool around with how much RAM you allocate to these things, so maybe you don’t have a machine with 128 gigs of RAM, only one with 64. Maybe I’ll only send it 12 jobs. Maybe I have a machine with lots of CPU cores. This way you can size the RAM, CPU, and the number of parallel requests, so each tier 2 node can run on different hardware with a different number of concurrent requests it can handle.
Marc-André | Ellipfra: If I don’t use the health check and the tier 2 receives a 31st request, does it error out and the tier 1 retries?
Matthew: Yes. If you try to send a job to the tier 2 and it’s not available, it will error out. So if you don’t want to do this health checking, you can let it error out, and eventually, you might get the DNS for one of the tier 2s that actually works.
Configuration: tier2 (continued with more detail from Matthew)
- 128 GiB RAM
- 14 CPU Cores
Add as much depending on what machines you have available, add RAM or CPU or whatever. I’m using the example we have, but feel free to change it depending on what you have, and it really varies based on the subgraphs. For example, there’s a Bitcoin subgraph where somebody’s doing ordinal processing, and you need gobs and gobs of RAM for that one to work. For the average Substreams, this is going to be fine; it’s probably overkill.
You’ll notice in the tier 2 configuration, there are no S3 buckets specified because tier 1 will pass the configuration for the specific chain to tier 2. Remember, the tier 2 nodes are blockchain-agnostic. They can process a Solana load, an Ethereum load, and a Polygon load all at the same time. They count each as one of the 30 requests in this example.
We don’t actually specify the details of where to find the blocks or where to write the cache. It’s not specified here. When tier 1 connects to tier 2, it tells it all that information, so it passes the parameters from the tier 1 configuration to tier 2, and then tier 2 knows how to interact with the storage.
Tier 2 does not pass the results back to tier 1. Tier 2 writes the results back to the storage and then tells tier 1 it’s finished and ready to accept another job.
Warning: Don’t expose tier 2 to the public!
Tier 2 nodes accept configuration parameters, so you don’t want to be exposing that to the public.
Monitoring: tier 2
Watch the recording from 29:08 and follow along as Matthew shares some monitoring examples for tier 2.
When you’re starting out, you don’t need a TB of RAM, you can start with a lot less. Based on the amount of hardware you have, that’s how fast it will process the Substreams job. More hardware will go faster, but less hardware will still work.
Configuration: tier 1
- 25 GiB RAM
- 4 CPU Cores
- Scale according to load
start:
args:
- substreams-tier1
flags:
log-verbosity: 0
log-to-file: false
advertise-chain-name: mainnet
common-live-blocks-addr: eth-sf-relayer-v4.service.march.consul:9000
common-merged-blocks-store-url: s3://…
common-one-block-store-url: s3://…
common-forked-blocks-store-url: s3://…
common-auto-mem-limit-percent: 90
substreams-rpc-endpoints: <http://eth-erigon.service.march.consul:8545/>
substreams-state-store-url: s3://…
substreams-tier1-grpc-listen-addr: :9000
substreams-tier1-subrequests-endpoint: substreams-tier2-v1.service.march.consul:9000
With more detail from Matthew
Here’s an example of tier 1 configuration. In our setup for tier 1 nodes, we actually run multiple tier 1s on the same server with overlapping RAM. So the server has 128 gigs of RAM, and we’ve allocated 25 gigs to this tier 1 node, but there are 20 tier 1 nodes, so if you do the math, 25 x 20 doesn’t fit in 120 gigs of RAM. It depends on how busy it is, so we’ve taken the approach that if it’s too busy, then the whole machine will crash, but on average, we don’t have that much load going from one to another. So again, scale it according to the load you have.
Above, we’ve got a much bigger configuration file, and as I said, this configuration is going to be passed to the Substreams tier 2 node, so then it knows where the S3 buckets are. We’re reading the relayer, and we’re also using Consul for publishing where the relayers are available: merged blocks, one block, forked blocks—there are S3 buckets for that. substreams-state-store is the cache files for Substreams. Then the last line specifies where the tier 2 nodes are: substreams-tier2-v1.service.march.consul:9000. We always use port 9000. You don’t have to use port 9000, that’s just how we have things set up in our environment.
Make sure the Substreams tier 1 is pointed at wherever the DNS is for your tier 2. This Substreams tier 2 DNS entry will only return results for the ones that are healthy. If none of them are healthy, you get no answer.
Monitoring: tier 1
Watch the recording from 33:13 and follow along as Matthew shares some monitoring examples for tier 1.
This monitoring is looking at Ethereum. Tier 2 is generic—it processes all the blockchains that we support, whereas tier 1 is Ethereum only.
The last chart (below) shows how many rejected requests, so the tier 2 nodes are returning the “I’m busy, go away” messages. You can keep track of how often that happens. For example, in our case, if the health check only runs every 5 seconds, there may be a period of time where the tier 2 node is busy but the DNS is still returned as valid, and in this case, we’re catching this.
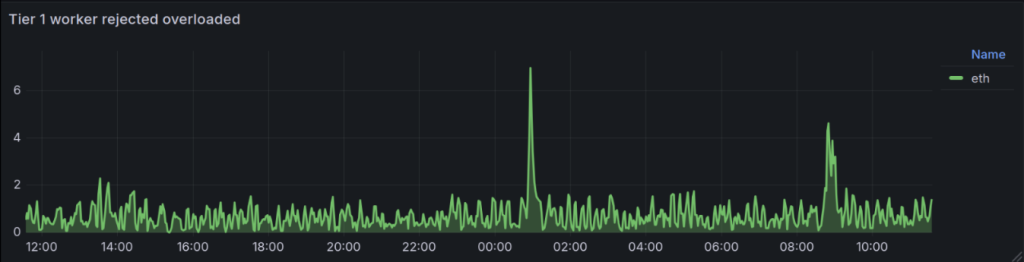
Monitoring and logging
- Prometheus and Grafana are mandatory to gain an understanding of what is happening
- Run node-exporter and/or cAdvisor to see what is going on with your bare-metal/container systems
- The Substreams Grafana charts are relatively simply created:
- E.g. sum(substreams_tier1_active_worker_requests) by (network)
- (you need to add your own labeling in Prometheus)
- Put logs in a central logging system so you don’t have to search everywhere in case of errors
With more detail from Matthew
Substreams tier 1 and tier 2 export a bunch of metrics. See the example above.
You’ll need to add your own labeling into Prometheus so you can see which network is which.
I really recommend putting logs into a central logging system, so if you’re trying to find out why a Substreams fails, you’re not looking at all the logs from every single tier 2 node.
Wrap up
- Sizing numbers are only guidelines to get you started
- What works for you depends on your hardware:
- NVME vs. HDD storage
- CPU/RAM speed
- And the actual Substreams you’re running:
- Some are quite complex and take lots of CPU
- Others are very simple
- Some do a lot of eth_call, which means the CPU is waiting on archive node
- We opted for HDD storage for S3
- And older CPUs (e.g. Xeon Gold 6148) for Substreams
- But lots of CPUs and RAM
- You can use whatever hardware you have available
- Ideally, you want a scaling solution like Kubernetes (k8s), but it can work without
- Substreams does not use the Firehose search index
With more detail from Matthew
The sizing numbers are just to get you started. This is going to be based on your experience, hardware, and subgraphs you’re running. This is not a set-it-and-forget-it. You’re going to have to look at those metrics to understand if you’re over-provisioning hardware too much and what the situation is. If you want advice in certain situations, feel free to ask in the Discord channel. But it’s an art more than a science to configure the load.
We’re using HDD storage, so our Ceph server is on HDD, which is slower. For example, when a tier 2 node gets a workload from a tier 1, there may be a slight delay before it can start working on stuff because it has to wait for the storage coming from the S3 bucket for the hard disk to send it. Same with writing it back. So the tier 2 nodes spend a bit of idle time waiting for the storage. If you have really fast storage, that idle time goes away, and you could spin up fewer tier 2 nodes.
Some Substreams are complex and take a lot of CPU, and some are simple. Maybe they have tons of modules or only have one, so the actual load will vary from one Substreams to the next. Some do a lot of ETH calls, which means your tier 2 node is waiting on your RPC node to answer, so they might be sitting idle because you overloaded your archive node answering ETH calls.
As you scale up your tier 2 nodes, you may also need to scale up your archive node if you want to run a lot of tier 2s in parallel and you’re doing a lot of ETH calls. The number of ETH calls depends on the subgraph; some do them and some don’t.
We opted for older CPUs because they’re more affordable. We have lots of CPUs and RAM. For Substreams, you don’t need the biggest, fastest, and best machine, you just need a lot of CPUs if you want to do things fast. Find your favorite used hardware reseller for hardware—that will work perfectly fine for Substreams.
From a scaling perspective, ideally, you’d want to put this in Kubernetes so that the tier 2 nodes can scale up and down, but if you don’t have Kubernetes and you’re willing to allocate hardware just for tier 2s, you can do that too. Currently, that’s what we do. We’re moving towards Kubernetes, and we’ve done some presentations here on Kubernetes:
- The Graph Indexer Office Hours #180 (Pinax’s setup)
- The Graph Indexer Office Hours #182 (Talos Linux)
We’re going to move our Substreams into Kubernetes, but our current deployment is not using Kubernetes yet. It’s using the “Matthew Scaler,” so whenever I see there’s extra load, I need to shuffle it around.
Q&A [40:03]
Gemma | LunaNova: How many Substreams subgraphs are there? Out of interest.
Matthew: Good question! I don’t know off the top of my head.
Marc-André | Ellipfra: With curation, 5-6.
Matthew: There are more Substreams-powered subgraphs that are not on the network yet or not available for indexing rewards. There’s definitely a whole bunch there, and you can use Substreams for reasons other than Substreams-powered subgraphs. Substreams will write into a webhook, Discord channel, PostgreSQL database, or ClickHouse, and then you can use that to do analytics or whatever else.
Mack: Here is the coolest use case I’ve come across built with Substreams: Roll a Mate
- Force transfer tx failure
- Listens for them on mempool
- Executes them on L2
- Finality changes balances
Yaro | Pinax: Do you ever delete old stale Substreams cache?
Matthew: Yes, I wrote a script and used 30 days. If a new cache file has not been written in at least 30 days for a Substreams, then I delete the entire cache for that Substreams. The cache files are organized by module ID, so if you do Substreams info on a subgraph, it will give you the module hashes and then the cache files are organized as one directory per cache. A single Substreams may have multiple modules, so you may have multiple cache files. The files are named after the block number, and if you look at the dates on them, you’ll see when they were written. That’s how we do it currently. I think StreamingFast has a more advanced system where they’re writing cache information into a database. I’m sure we’ll work on something that allows people to clean things up easier in the future. Currently, there’s no auto-clean-up, so you need to write a script yourself.
Yaro | Pinax: Would be cool to have a UI to work with all those cache files.
Vince | Nodeify: When you need to roll back Firehose, what work needs to be done on Substreams, if any?
Matthew: Great question. On occasion, some blockchains have weird things happen where you need to roll back blocks. Normally, you would consider a finalized block to be a finalized block, but we have seen some chains in the past where that is not the case. So in this situation, you need to remove Firehose blocks, remove Substreams cache files, let that replay, and then rewind the subgraph. Because finalized blocks are supposed to be finalized, there isn’t an automated way to recover when they’re not. You do need to remove merged block files from Firehose, remove Substreams cache files (these are by block number so you can easily find which ones you need to remove—you don’t have to delete the entire cache for one Substreams), let it catch up and then rewind subgraphs.
There is another situation where we occasionally find a bug in Substreams, and you do need to delete cache files that are impacted by that bug. Substreams has a versioning field, so you can increase the version number, and then Substreams will write new cache files in a new directory for you. Then you can delete the old ones.
In a recovery scenario, you don’t want all your subgraphs to start failing while you’re waiting for the Substreams files to get regenerated, so you should have an off-stream process to generate those files, do what you need to do, and then switch the live system over to the new stuff. That’s an advanced topic; I’m happy to chat with people if you want. So there are a few things that are still quite manual.
Mack’s question for indexers
If there’s anyone who is running a Sonic or Abstract indexer, please reach out to him because he would love to collaborate.
Matthew: Pinax has a Sonic endpoint.
Abel | GraphOps: Next week, Mode Network is coming to IOH as part of the chain watch.
Kate | InfraDAO: WOO HOO MODE! Rewards should be live soon!




always great tor ead those