


TL;DR: Introducing Substreams' new index module! The StreamingFast team joins episode #159 to introduce their latest development, index modules, and how they will result in improvements for indexers.
Opening remarks
Hello everyone, and welcome to the latest edition of Indexer Office Hours! Today is May 28, and we’re here for episode 159.
GRTiQ 170
Don’t miss the GRTiQ Podcast with Joe Vezzani, Co-founder and CEO at LunarCrush. This leading platform leverages social media analytics to provide actionable insights across many markets, including cryptocurrencies.
Repo watch
The latest updates to important repositories
Execution Layer Clients
- Avalanche: New release last v1.11.6 :
- Fixed performance regression while executing blocks in bootstrapping
- Fixed peer connection tracking in the P-chain and C-chain to re-enable tx pull gossip
- Fixed C-chain deadlock while executing blocks in bootstrapping after aborting state sync
- Fixed negative ETA while fetching blocks after aborting state sync
- Fixed C-chain snapshot initialization after state sync
- Fixed panic when running avalanchego in environments with an incorrectly implemented monotonic clock
- Fixed memory corruption when accessing keys and values from released pebbledb iterators
- Fixed prefixdb compaction when specifying a nil limit
- Added additional API metrics
- Arbitrum-nitro New releases:
- v2.4.0-rc.1 :
- Allow 0x prefix for allowed-wasm-module-roots flag
- Implement tracing and CPU profiling of long-running block creations
- Create streams in Redis client, poll on it in Redis server
- v2.4.0-beta.1 :
- Arbitrum Stylus:
- Disable LLVM support in JIT build in docker
- Error early when missing asm
- Separate wasm asm database
- Stylus cache tag
- Fix lastUpdateTimeOffset -> ArbitrumStartTime
- Use saturating math for hoursSinceArbitrum
- Backward compat validation docker
- Support pre-stylus wasm module roots for validation
- block_validator: fail but don’t segfault if no validator
- Fix off-by-one in data poster nonce check
- Arbitrum APIBackend’s GetTransaction should return false when tx is not found (fixes eth_getTransactionByHash when the transaction is not found)
- Unified writer interface for data availability providers
- Adds blocks’ hashes to the sequencer’s feed
- Compare computed block hash with hash provided through input feed
- More descriptive jit machine accept() errors
- Merge in upstream go-ethereum v1.13.12
- Fix signed saturating math functions
- Fix zero bid in data poster
- Assume stake is elevated if currentRequiredStake reverts
- Improve error messages for syncing nitro nodes with a beacon chain client lacking old enough blobs for sync
- fix: CleanCacheSize from hashdb.Config expects a value defined in bytes
- Adds apt-get update to wasm-libs-builder
- Gracefully shutdown consumer on interrupts
- Arbitrum Stylus:
- v2.4.0-rc.1 :
- Heimdall: New release v1.0.6 :
- This release contains a fix for the milestone/checkpoint module
Consensus Layer Clients
Information on the different clients
- Nimbus: New releases:
- v24.5.1 :
- Nimbus v24.5.1 is a low-urgency release with stability as well as beacon and builder API improvements. It addresses a compatibility issue with certain hardware where v24.5.0 would not properly launch.
- v24.5.0 :
- Nimbus v24.5.0 is a low-urgency release with stability, performance, and beacon and builder API improvements.
- v24.5.1 :
Graph Stack
- Graph Node: No new releases ( last v0.35.0 ):
- This is now ready to be used on mainnet . For more information, check The Graph Council Proposals or the Feature Support Matrix.
- Subgraph-radio: New release 1.0.6-alpha.1
Graph Orchestration Tooling
Join us every other Wednesday at 5 PM UTC for Launchpad Office Hours and get the latest updates on running Launchpad.
The next one is on June 5. Bring all your questions!
Protocol watch
The latest updates on important changes to the protocol
Forum Governance
Contracts Repository
- fix: slashing horizon delegation #976 (merged)
- [WIP] Graph Horizon #944 (open)
- feat: add linked list library #975 (merged)
- [WIP] Graph Horizon: Staking unit tests #974 (merged)
- Tmigone/horizon staking revamp #973 (merged)
- [WIP] Horizon: fix unit tests and refactor #972 (merged)
Network Subgraphs
- Analytics subgraph: Performance improvements (v1.1.0)
Open discussion
Enol, a developer relations engineer from StreamingFast, introduced the team’s latest development.
The Medium article: Substreams’ new index module brings a major performance boost
Enol talked about indexes. The team has deployed a new module that you can use in Substreams. An index module is a module that has been pre-cached for some specific data.
Here’s an example from the documentation. Learn more about it, try it out, and send the team feedback.
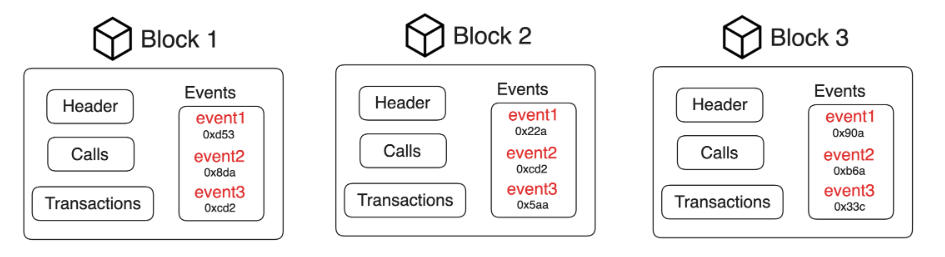
Source: Indexes documentation
The problem that we’re trying to solve with indexes is not to consume unnecessary data. In the diagram above, you can see three blocks with their corresponding data. Consider that you want to retrieve all the events where log.address == 0xcd2…. Without an index, you would have to go through the data of every block, but with an index, you can skip the blocks that do not contain the event that you want.
Index modules create a cache for every block of potential data that could be in the block you’re looking for and have that cache looked at before decoding the block data.
So, in this case, instead of going through every block looking for this event address, you would have a cache for every block of data. Before actually decoding the block itself, you take a look at the cache data, look for the event, and if it’s there in the cache, that event is going to be contained within the block. If not, you simply skip the block.
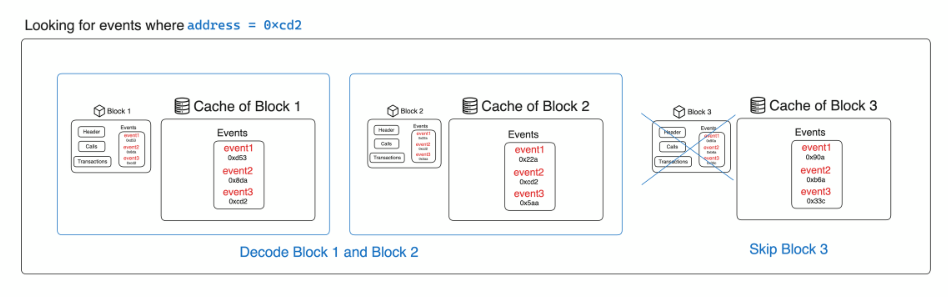
This is a way to reduce the amount of data that you read and the time that you spend because you don’t have to decode the specific block that doesn’t contain the event you’re looking for.
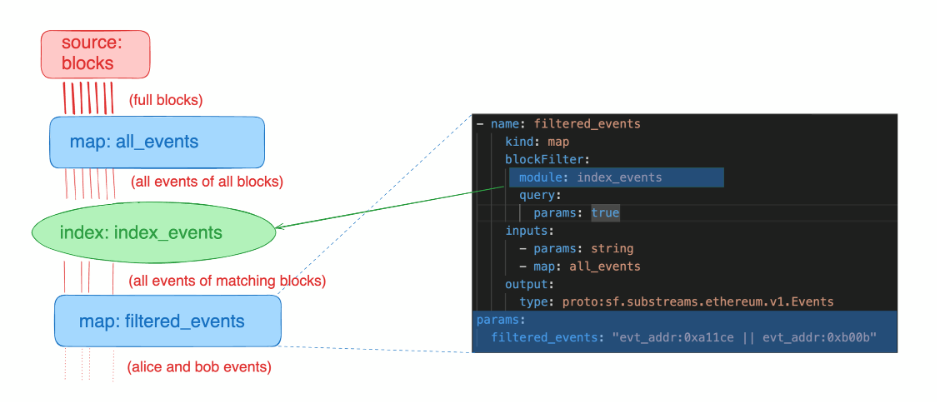
This is a graphical view of the hierarchy. You have this source block, a map (a mapper that gets all the events), and the index event module that indexes all the events of that block through the address of the event. Then, you can consume that index event module through another mapper, which is called future events, and you can add the filters for that event here.
In this case, you’re looking for events with addresses of this kind. You will basically skip all the blocks that do not contain events with this address or events with this other address. That’s the basic functionality behind the new index modules.
StreamingFast is pleased to have announced this, as they believe it will help indexers a lot. They’ve seen massive improvements for some specific modules, and they’re always looking for feedback. So, if you try it out, just let them know.
💡 The most important thing for indexers to note is that you don't have to change anything. This will load data into the cache that you've already configured for Substreams. So, it's really easy from a DevOps perspective: do nothing.
Substreams packages:
GitHub issues:
- Allow dynamically changing substreams-tier1-max-subrequests #276
- Improve protocol versioning between tier1 and tier2 #468
- Huge substreams overload tier 2 nodes #458
Questions:
1. How much disk space do the bloom filters take?
Answer: That’s a good question. We don’t know yet, and we’ll need to investigate.
2. Does the index cache persist between packing version changed of the Substreams?
Answer: Yeah, I assume it does. That’s a specific module that you’re consuming. If you don’t change it, the cache shouldn’t be cleared.
3. Can you discuss the Substreams use cases where these indexes result in the greatest speed-up? Sparse subgraphs presumably?
Answer: Yeah, there are some use cases where indexes are resulting in the greatest speed-up. This is generalized for any blockchain, right? So, for instance, for Solana, which has a big, raw block that has all the information, I guess it could be very useful, right? Not actually decoding the block if the data is not there. So, for a specific chain like Solana, it would be super, super useful.
4. What indices outside of the event log address are available? Do we have indices for filtering on a topic?
Answer: The indexes are totally up to you. I mean, these are just keys that you put in a cache-like store, right? So, whenever you want to create the module, you are selecting which specific data you want to index, and which specific data you want to include in this store. So, yeah, sure, no problem, you can index any data contained within the data model.





No Comments